U
Utente cancellato 159815
Ospite
[ASPETTANDO NVIDIA VOLTA]

SPECIFICHE FINORA NOTE:
Processo produttivo: 16 nm finFET
Ram: HBM 2
Modelli GPU: GV104, GV102, GV110

Così avevamo salutato il 3d aspettando Maxwell, per passare in quello relativo alle GPU effettivamente annunciate, oggi partiamo con un altro step evolutivo delle architetture Nvidia, e quel Maggio 8-11 2017 pare sia diventata una data significativa anche per l'annuncio delle architetture consumer gaming potenziate con i vari GV104, GV110 e GV102 di cui però ancora non si conoscono le prerogative.
SPECIFICHE FINORA NOTE:
Processo produttivo: 16 nm finFET
Ram: HBM 2
Modelli GPU: GV104, GV102, GV110
Quello che sappiamo, per ora, è che si sta pensando, a differenza di Pascal che conserva SM del tutto simili a Maxwell, a un significativo step architetturale, dopo quello inerente il PP simile a quello che ha consentito a Maxwell di ottenere il 40% di performance in più dai Cuda Cores e il 50% di consumi in meno.
Si era parlato anche di PP a 10 nm, ma è stato subito smentito ed è quasi confermato che sarà sviluppato con il medesimo PP di Pascal, i 10nm saranno saltati in favore dei 7 nm per le future architetture dalle ultime voci di corridoio.
Come memoria si parla, per ora, unicamente di Ram HBM2 e ritorna alla grande la voce di Nvlink, ma questa volta anche per il mercato High Performance Gaming.
Ricordo che nella prima Road Map delle nuove architetture Pascal non veniva nemmeno citato:

Che Nvidia sia passata a un modello di upgrade dell'architettura simil Tick Tock Intel mi pare alquanto probabile, anche perchè già si parla di VOLTA revisionato su processo produttivo nuovo con un trattamento simil Maxwell-Pascal.
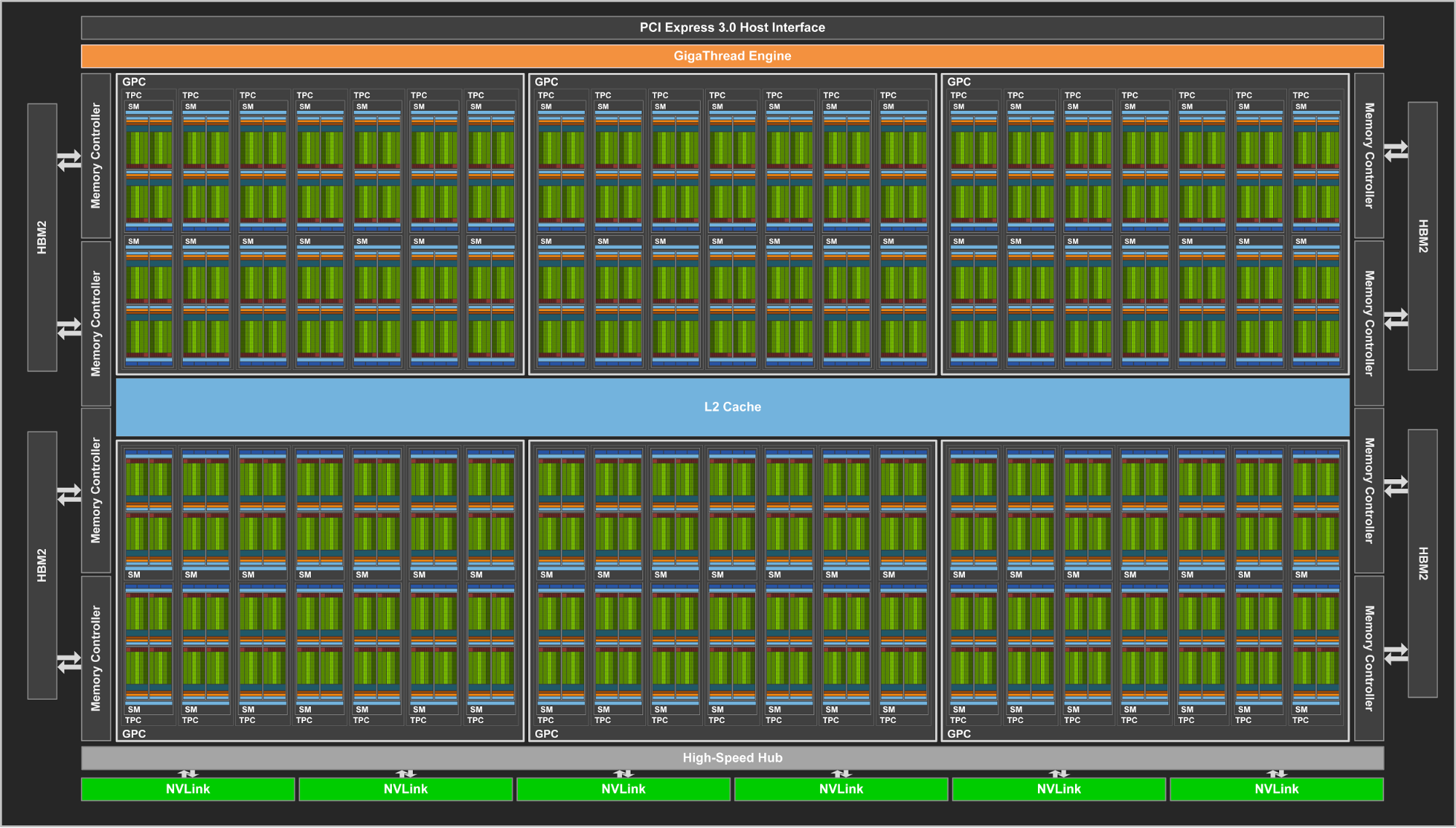
VOLTA V100 (il chippone)


ARCHITETTURA:
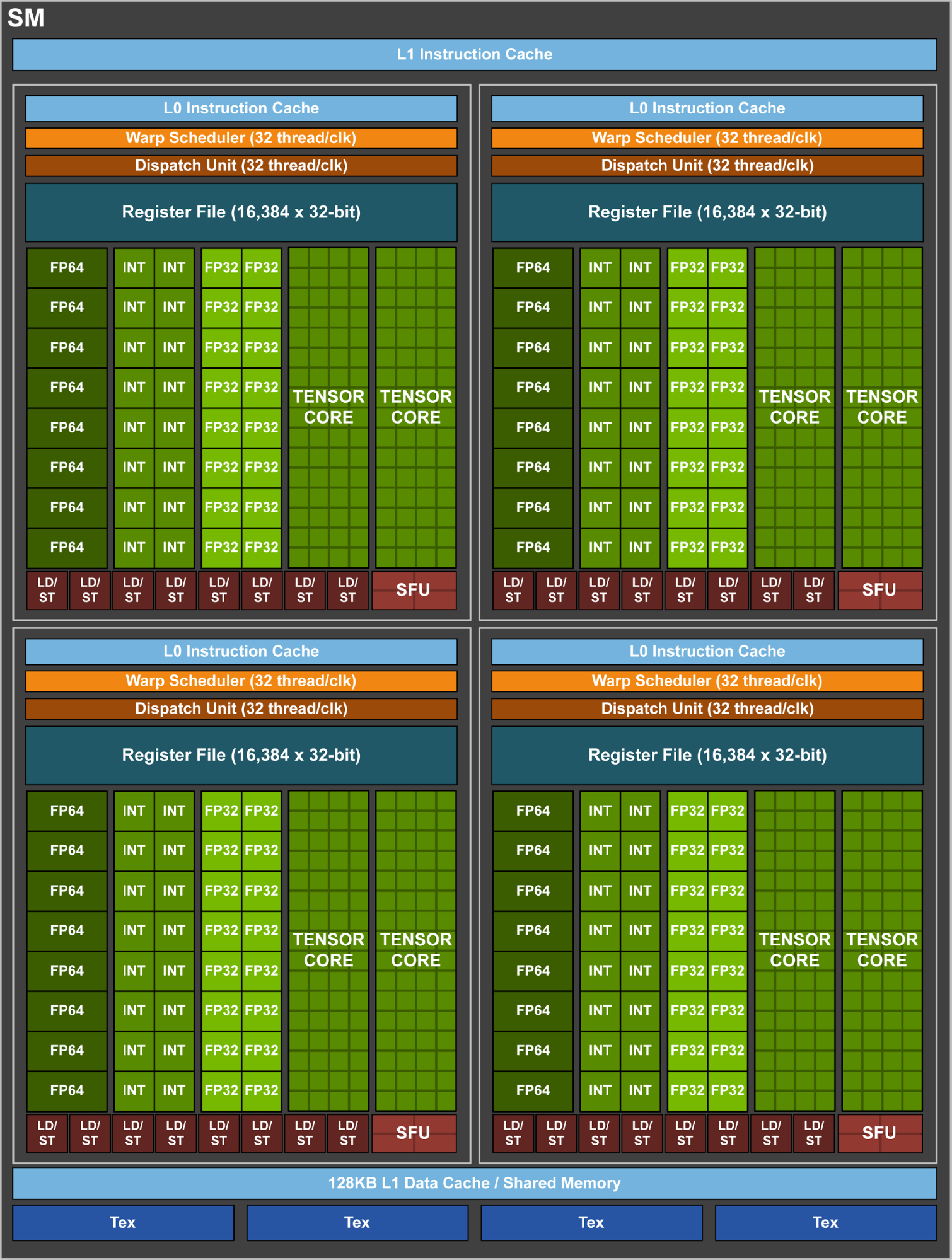
DETTAGLIO SM
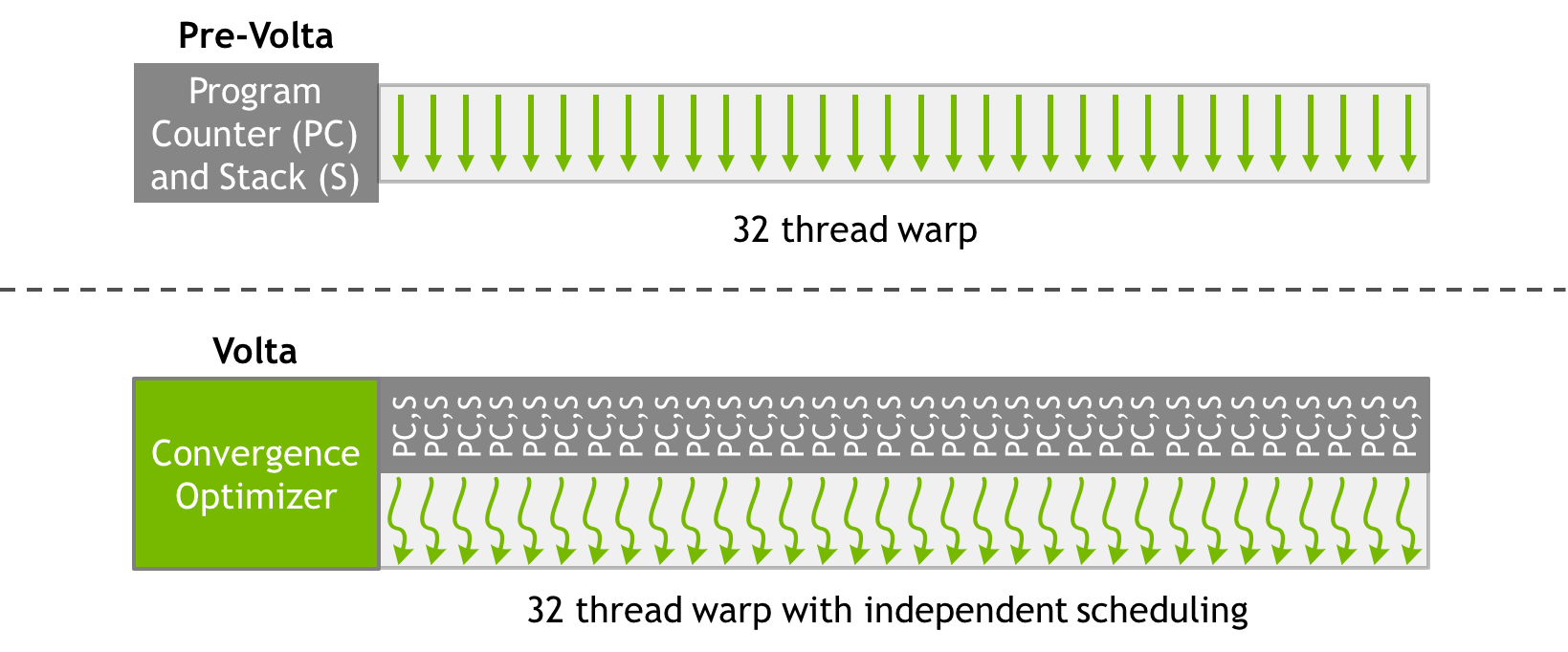
IL SUPERAMENTO DEL WARP SCHEDULER
ARCHITETTURA:
DETTAGLIO SM
IL SUPERAMENTO DEL WARP SCHEDULER
Volta’s independent thread scheduling allows the GPU to yield execution of any thread, either to make better use of execution resources or to allow one thread to wait for data to be produced by another. To maximize parallel efficiency, Volta includes a schedule optimizer which determines how to group active threads from the same warp together into SIMT units. This retains the high throughput of SIMT execution as in prior NVIDIA GPUs, but with much more flexibility: threads can now diverge and reconverge at sub-warp granularity, and Volta will still group together threads which are executing the same code and run them in parallel.
In pratica una maggiore parallelizzazione dei Threads in fasi di elaborazione, una maggiore flessibilità, e sarà interessante capire ora le performance in ambito Async compute.
Ultima modifica da un moderatore:

