

Infinity Fabric è stata particolarmente utile nel mondo dell'informatica ad alte prestazioni (HPC), come evidenziato dalla presentazione di AMD alla conferenza HPC Rice Oil and Gas.
AMD ha inizialmente annunciato al suo evento Next Horizon nel 2018 che avrebbe esteso Infinity Fabric anche alle GPU per data center MI60 Radeon Instinct per consentire un collegamento a 100 Gbps tra GPU, proprio come la tecnologia NVLink del Team Green.

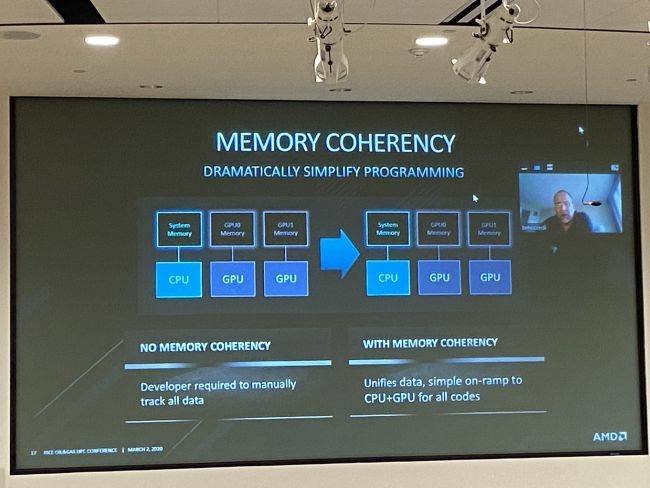
L'evento annuale di Rice Oil and Gas non si è ancora concluso, ma secondo un tweet di Addison Snell, analista di Intersect 360 Research, il Team Red ha annunciato che le future generazioni di accoppiate Epyc e Radeon includeranno coerenza di memoria / cache condivisa tra GPU e CPU, simile a quella già implementata sui prodotti Raven Ridge, le APU Ryzen basate su architettura Zen.
Abbiamo anche visto alcune slide presentate a Rice Oil and Gas, per gentile concessione di Hatem Ltaief, ricercatore senior dell'Extreme Computing Research Center.
I grafici di AMD evidenziano il divario nell'efficienza energetica di varie soluzioni di calcolo, come SoC e FPGA semi-personalizzati, GPGPU e core di calcolo x86 generici, e mettono in evidenza i FLOPS sia in termini di consumo energetico che di superficie del die.
Come potete vedere, le CPU per uso generico sono più lente, ma le ottimizzazioni per il codice vettoriale che utilizzano percorsi SIMD dedicati possono migliorare le prestazioni. Le GPU mantengono ancora un vantaggio in termini di efficienza energetica e area occupata.
Sfruttare la coerenza della cache, come sulle APU Ryzen, consente di sfruttare il meglio di entrambi i mondi e, secondo le slide, unifica i dati e fornisce un "semplice passaggio alla CPU + GPU, per tutti i codici". Un'architettura di memoria unificata riduce gran parte del carico di programmazione.

AMD ha abbracciato l'architettura dei sistemi eterogenei (HSA) per legare insieme i blocchi a funzioni fisse di Carrizo. HSA fornisce un pool di memoria virtuale condivisa coerente con la cache che elimina i trasferimenti di dati tra i componenti per ridurre la latenza e migliorare le prestazioni.
Quando una CPU completa un elaborazione dati, questi potrebbero comunque richiedere l'elaborazione nella GPU. Ciò richiede che la CPU passi i dati dal suo spazio di memoria alla memoria della GPU, dopodiché la GPU potrà elaborarli e restituirli alla CPU. Questo processo complesso aggiunge latenza e comporta un calo delle prestazioni, ma la memoria condivisa consente alla GPU di accedere alla stessa memoria utilizzata dalla CPU, riducendo e semplificando lo stack del software.
I trasferimenti di dati consumano spesso più energia rispetto al calcolo effettivo stesso, quindi l'eliminazione di tali trasferimenti aumenta sia le prestazioni che l'efficienza. L'estensione di tali vantaggi a livello di sistema condividendo la memoria tra GPU e CPU discrete offre ad AMD un vantaggio tangibile rispetto ai suoi concorrenti nel settore HPC.
AMD non promuove più attivamente HSA nelle comunicazioni con la stampa, pur essendo ancora un membro del gruppo. È chiaro che i principi fondamentali dell'architettura open sopravvivono nella nuova implementazione proprietaria, che probabilmente si appoggia al suo ecosistema software ROCm.
AMD ha tracciato un percorso in questo senso e ottenuto grandi vittorie nei sistemi di classe exascale, incluso il recente supercomputer El Capitan che vanta una potenza computazionale di 2 exaflop e sfrutterà Infinity Fabric 3.0. C'è da dire comunque che anche Intel non è da meno e sta lavorando alla sua architettura Ponte Vecchio, che alimenterà il supercomputer Aurora presso l'Argonne National Laboratory del Dipartimento dell'Energia degli Stati Uniti.
L'approccio di Intel si basa fortemente sul modello di programmazione OneAPI e mira a collegare pool di memoria condivisi tra CPU e GPU (chiamati simpaticamente Rambo Cache). Sarà interessante apprendere di più sulle differenze tra i due approcci.
Nvidia potrebbe soffrire nel regno del supercomputer perché non produce sia CPU che GPU e, pertanto, non può abilitare funzionalità simili. Questo tipo di architettura, e i modelli di programmazione unificata sottostanti, sono richiesti per raggiungere prestazioni di classe exascale con consumi accettabili? Chissà, quel che è certo è che seppur Nvidia dovrebbe offrire funzionalità di coerenza (grazie alla presenza all'interno del consorzio CXL), sono AMD e Intel ad aver vinto contratti estremamente importanti con il governo statunitense.