
Nelle scorse settimane siamo volati a Phoenix con Intel per scoprire tutti i segreti di Panther Lake, la prossima generazione di chip mobile che promette di rivoluzione i notebook (e non solo). L’evento non si è concentrato sui modelli specifici della lineup, che verranno svelati più avanti e di cui comunque ci sono già diverse indiscrezioni, ma sulle novità architetturali della piattaforma, che mette parecchia carne al fuoco.
Anche per Intel la parola d’ordine è intelligenza artificiale e nella creazione di Panther Lake ha lavorato in questa direzione, con l’obiettivo di soddisfare le esigenze del mercato. L’azienda afferma che entro il 2028 l’80% dei carichi IA sarà in inferenza e che l’AI agentica è il mezzo per sbloccare il vero valore dell’intelligenza artificiale, motivo per cui si sta muovendo per creare sistemi scalabili ed eterogenei, perfetti per svolgere questi compiti.
.png?width=896 "Clicca per vedere l'immagine originale")
.png?width=896 "Clicca per vedere l'immagine originale")
.png?width=896 "Clicca per vedere l'immagine originale")
Sono molte le tecnologie impiegate da Intel per raggiungere il proprio obiettivo: oltre al nodo 18A, ci sono anche i nuovi transistor RibbonFET e l’uso di PowerVIA per l’alimentazione. RibbonFET offre un miglior controllo dei gate, è più scalabile grazie all’uso di fogli di silicio sovrapposti e da maggior flessibilità ai designer; PowerVIA permette di aumentare fino al 10% la densità e l’uso delle celle grazie al fatto che ora l’alimentazione arriva dal retro, inoltre assicura fino al 30% di IR Drop in meno dal package al transistor.
Rimane la struttura a tile, se ne va la memoria integrata
Panther Lake nasce per massimizzare l’efficienza a parità di prestazioni, scalare il throughput su CPU, grafica e AI e aumentare la flessibilità di prodotto, adattandolo alle diverse richieste del mercato; l’obiettivo di Intel è quello di unire l’efficienza di Lunar Lake e le prestazioni di Arrow Lake-H. Per raggiungere questo obiettivo viene riproposta la struttura a tile vista con Lunar Lake: la base fisica è il packaging Foveros-S 2.5D con fabric scalabile di seconda generazione che collega Compute tile, GPU tile (separato per scalare i segmenti) e Platform Controller tile (PCD), mantenendo un sistema coerente cross-tile e interconnessioni die-to-die dedicate.
Sparisce invece la memoria sul chip vista in Lunar Lake: come avevano già anticipato diverse voci, Intel sembra aver abbandonato quella strada, almeno per il momento, in favore di una maggior flessibilità di configurazione.

Come vedremo tra poco Panther Lake avrà diverse varianti, ma la piattaforma adotta la stessa “impronta” di package per tutte e raggruppa l’I/O e la connettività nel PCD, mentre i core risiedono nella Compute tile. Avere la GPU tile separata permette invece di scalare al massimo la grafica tra i diversi segmenti.
Compute tile: Cougar Cove, Darkmont e LPE-core su Intel 18A
La Compute tile ora è prodotta con il processo Intel 18A e ci sono nuove architetture sia per i P-Core, basati su Cougar Cove, che per gli E-Core e gli LPE-Core, basati su Darkmont. Lato front-end, i P-core Cougar Cove integrano un refactor del Branch Prediction Unit (derivato e migliorato rispetto al BPU “novel” di Lunar Lake), TLB con 1,5 volte la capacità in più così da gestire workload moderni e disambigurazione della memoria, per prestazioni più affidabili. Ci sono poi 18 execution port e fino a 18MB di cache L3, a seconda della configurazione.
Gli E-core Darkmont puntano a prestazioni in linea con Raptor Cove (l’architettura di Raptor Lake) a potenze inferiori e introducono miglioramenti su nanocode, disambiguazione della memoria e deep queuing per scalare il parallelismo a consumi contenuti, oltre a più banda per la cache L2. Gli LPE-core sono anch’essi basati su architettura Darkmont e rimangono i core più efficienti all’interno di Panther Lake; in questa generazione godono di un aumento della cache L2 condivisa rispetto a Lunar Lake, che passa a 4MB.
.jpg?width=896 "Clicca per vedere l'immagine originale")

.jpg?width=896 "Clicca per vedere l'immagine originale")
.jpg?width=896 "Clicca per vedere l'immagine originale")
.jpg?width=896 "Clicca per vedere l'immagine originale")
Non ci sono particolari indicazioni riguardo alle prestazioni, considerando che Intel ha mostrato dei grafici senza reali riferimenti, molto simili a quelli che solitamente vediamo con Apple e Qualcomm. L’azienda dichiara però che in single thread, Panther Lake è il 10% più veloce a parità di potenza rispetto a Lunar Lake e Arrow Lake-H, mentre è il 40% più efficiente a parità di prestazioni; in multi thread è invece il 50% più veloce di Lunar Lake a parità di potenza e il 30% più efficiente di Arrow Lake-H a parità di prestazioni.
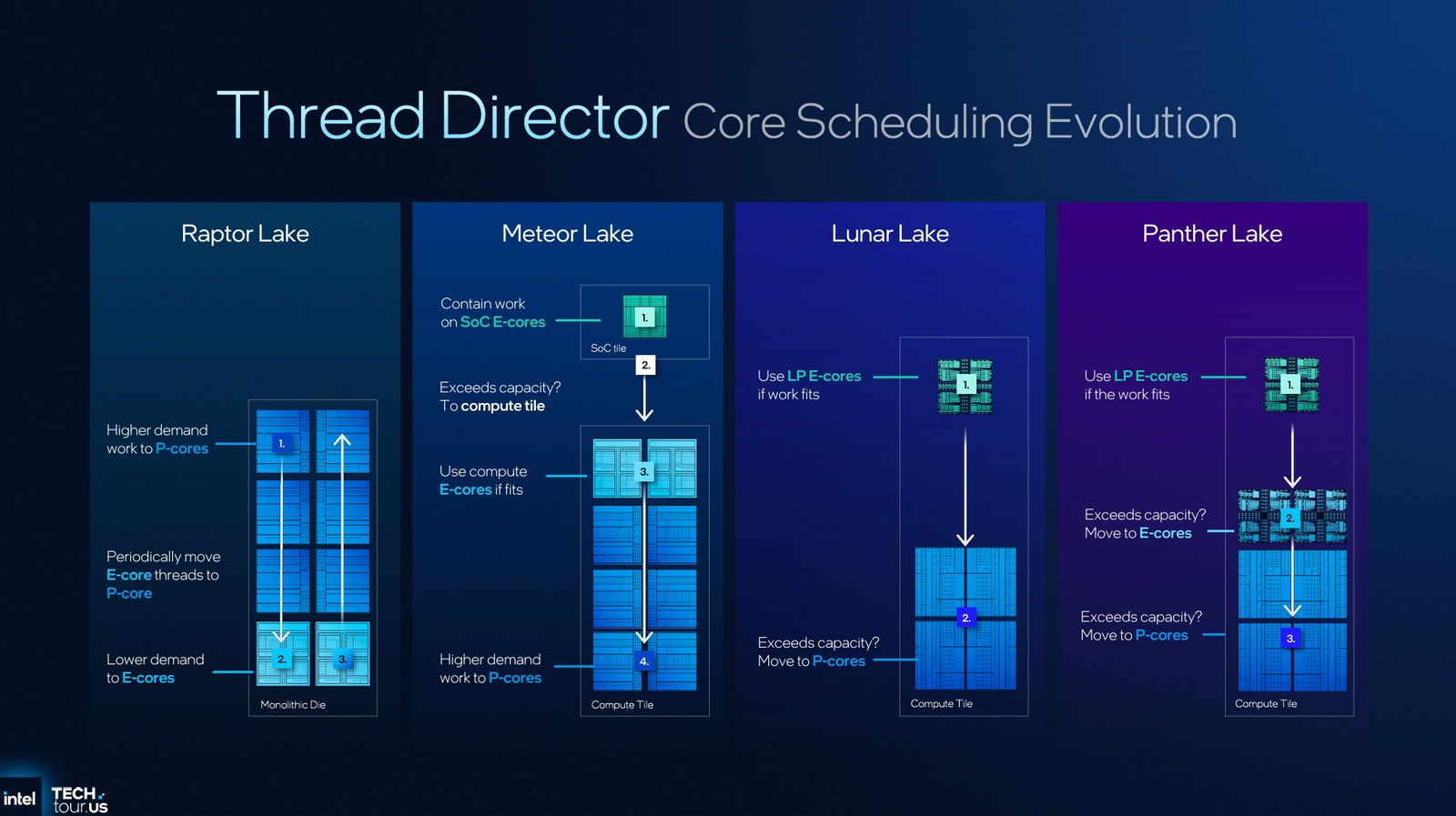
Novità importanti anche per Thread Director, che evolve i modelli di classificazione e la “intelligent thread guidance” per coprire più casi complessi, con esecuzione simultanea fra P-Core, E-core e LPE-core. Il sistema sfrutta ancora le tre zone di contenimento introdotte da Microsoft in Windows per Lunar Lake: Efficiency (i carichi stanno sugli E-Core), Hybrid/Compute (i carichi stanno sui P-Core), Zoneless (i carichi stanno su entrambi i tipi di core). Le nuove ottimizzazioni permettono di assegnare meglio le zone, ad esempio una videocall su Microsoft Teams con effetti video attivi, che ricade nella zona Efficiency, viene gestita quasi totalmente dagli LPE-core, liberando risorse per altre attività.
Tante opzioni per la memoria
Panther Lake supporta sia DDR5 in formato SO-DIMM che LPDDR5X, ma a seconda dello standard e della configurazione del chip ci sono opzioni diverse: in generale, sono supportate LPDDR5X fino a 9600MT/S e fino a 96GB di capacità, mentre lato SO-DIMM si arriva fino a 7200MT/s e 128GB.
La memory-side cache da 8MB e il memory controller sono stati inoltre spostati dalla Platform tile alla Compute tile, per ridurre le latenze del fabric su working set ampi.
GPU tile: Architettura Xe di 3ª generazione e novità per XeSS
Anche la nuova GPU Tile è ricchissima di novità, a partire dal processo produttivo: TMSC N3E o Intel 3, a seconda della versione. La GPU di Panther Lake, basata sulla nuova architettura Xe3, scala fino a 12 Xe-core con 12 unità RT e 16 MB di cache L2 e assicura, stando a quanto dichiarato, fino al 50% di prestazioni in più rispetto a Lunar Lake e fino al 40% di prestazioni per watt in più rispetto ad Arrow Lake-H.
Ovviamente i miglioramenti sono merito della nuova architettura, che offre 6 render core (e 6 unità ray tracing) per render slice rispetto ai 4 di Lunar Lake, per una maggior scalabilità, oltre a nuovi Xe Core con 8 vector engine da 512 bit che offrono fino al 25% di thread in più e il supporto alla dequantizzazione FP8, 8 XMX engine da 2048 bit capaci di arrivare fino a 120 TOPS, il 33% in più di cache L1 condivisa per SLM e nuove unità ray tracing con dynamic ray management, per la gestione asincrona del ray tracing.
.jpg?width=896 "Clicca per vedere l'immagine originale")
.jpg?width=896 "Clicca per vedere l'immagine originale")
.jpg?width=896 "Clicca per vedere l'immagine originale")
.jpg?width=896 "Clicca per vedere l'immagine originale")
.jpg?width=896 "Clicca per vedere l'immagine originale")
.jpg?width=896 "Clicca per vedere l'immagine originale")
Sul piano software, il driver stack introduce allocazione variabile dei registri (IGC), scheduler più rapido con direct preemption e supporto iniziale a DirectX Cooperative Vector, con driver preview e codice di esempio pubblicati a giugno 2025 in collaborazione con Microsoft per portare la matrix multiply accelerata anche dentro gli shader.
Su XeSS arriva la frame generation multipla
Una delle novità più importanti per la grafica di Panther Lake arriva dal software: per migliorare le prestazioni su piattaforme a basso consumo non basta una GPU potente, ma serve un approccio di rendering ibrido che mischia l’IA e la rasterizzanzione classica. Partendo da questo presupposto, che di fatto sta alla base di tutti gli upscaler, non solo XeSS, l’azienda ha sviluppato una nuova versione del suo algoritmo, che ora integra la generazione multipla di frame.
Similmente alla MFG di NVIDIA, anche il nuovo XeSS è in grado di generare fino a 3 frame aggiuntivi per ogni frame renderizzato, inoltre l’API non cambia, quindi i giochi XeSS 2 supporteranno XeSS 3 al lancio di Panther Lake e sarà possibile eseguire un ovveride della fram generation tramite Intel Graphics Software.
.jpg?width=896 "Clicca per vedere l'immagine originale")
.jpg?width=896 "Clicca per vedere l'immagine originale")
C’è poi anche il nuovo Intelligent Bias Control V3, ottimizzato per gli upscaler e che punta a massimizzare l’efficienza delle prestazioni in gioco: la nuova versione usa un algoritmo rinnovato e mette il carico sugli E-Core, dando così la possibilità al sistema di riservare molta più potenza per la GPU, in modo da avere performance migliori. Inoltre, per accelerare i tempi di caricamento Intel ha deciso di passare a shader precompilati: ora anziché essere compilati localmente, gli shader si trovano in un cloud Intel e verranno scaricati dal software grafico Intel in base ai giochi installati sul PC.
Durante l’evento l’abbiamo visto in azione su Painkiller e Dying Light The beast, entrambi in esecuzione su piattaforma Panther Lake: nel primo caso le sensazioni sono state positive, nel secondo meno, ma dovremo fare test approfonditi per capire davvero quanto c’è di buono nella tecnologia.
.jpg)
La buona notizia è che Intel darà una grossa mano in queste analisi grazie alla nuova versione di PresentMon, il software per catturare il framerate più diffuso e su cui si basano quasi tutti i programmi più famosi. Ci sono diverse novità degne di nota, dall’introduzione del percentile per tutte le metriche al nuovo parametro di animation error, ma la più interessante è senza dubbio la frame time differentiation: nel log frame renderizzati e frame generati saranno divisi, dando la possibilità di capire chiaramente qual è il framerate del gioco prima dell’intervento della multi frame generation.
NPU 5: aumentano l’efficienza e i datatype
Il blocco NPU di 5ª generazione migliora per efficienza per area (+>40% TOPS/mm²), nonostante l’uso di 3 Neural Compute Engine contro i 6 di Lunar Lake, e amplia la copertura datatype con il supporto nativo per FP8 (E4M3/BF8 e E5M2/HF8), mantenendo INT8/INT4 e FP16/BF16. Il MAC array raggiunge 4096 MAC/ciclo in INT8 e in FP8, oltre a 2048 MAC/ciclo in FP16, rimuove restrizioni di channel padding e integra conversioni dati native con pipeline di post-processing FP32 e nuove LUT programmabili per molte funzioni di attivazione (ReLU, GELU, Tanh, ecc.).
.jpg?width=896 "Clicca per vedere l'immagine originale")
.jpg?width=896 "Clicca per vedere l'immagine originale")
.jpg?width=896 "Clicca per vedere l'immagine originale")
.jpg?width=896 "Clicca per vedere l'immagine originale")
.jpg?width=896 "Clicca per vedere l'immagine originale")
A livello di piattaforma, Intel dichiara fino a 180 TOPS per l’IA combinando CPU (fino a 10 TOPS con VNNI/AVX), NPU 5 (50 TOPS) e GPU Xe3 (120 TOPS), con particolari benefici in termini di energia e tempo su pipeline text-to-image passando da FP16 a FP8, dove si ottengono risultati qualitativamente simili ma più velocemente e consumando meno energia.
Platform tile: connettività di ultima generazione e non solo
La nuova Platform tile integra Wi-Fi 7 Release 2 e Bluetooth Core 6.0: tra le novità principali del nuovo Wi-Fi troviamo single-link eMLSR (client MLO con una sola radio), multi-link reconfiguration e il coordinamento canali peer-to-peer per evitare interferenze con l’access point. Da notare inoltre che l’interfaccia CNVio 3 collega il modulo CRF al SoC a 11 Gbps, più del doppio rispetto a CNVio 2 che si fermava a 5 Gbps; si tratta di un requisito pratico per saturare la banda del Wi-Fi 7 integrato.
Lato Bluetooth, oltre alle funzionalità LE Audio / Auracast e al dual Bluetooth che sfrutta le stesse antenne del WiFi per migliorare le performance (fino a 52 metri di copertura, +5dB di sensibilità e +3dB in ambienti multipath), la piattaforma introduce la misura della distanza ad alta precisione grazie al ranging time-of-flight e phase-based, che assicura una precisione fino a 10cm; si tratta di un’ottima novità per applicazioni come trova il mio dispositivo, chiavi digitali, sicurezza e anche per la gestione energetica di periferiche fuori portata.
.jpg?width=896 "Clicca per vedere l'immagine originale")
.jpg?width=896 "Clicca per vedere l'immagine originale")
.jpg?width=896 "Clicca per vedere l'immagine originale")
.jpg?width=896 "Clicca per vedere l'immagine originale")
.jpg?width=896 "Clicca per vedere l'immagine originale")
.jpg?width=896 "Clicca per vedere l'immagine originale")
.jpg?width=896 "Clicca per vedere l'immagine originale")
.jpg?width=896 "Clicca per vedere l'immagine originale")
Ovviamente ci sono novità importanti anche lato software, con la nuova Intel Connectivity Performance Suite 5.0 che introduce il QoS “AI-aware”: dando priorità al traffico AI del client, Intel mostra fino al 30% circa di reattività in più in determinati scenari.
Sul fronte I/O, la Platform tile offre fino a 20 linee PCIe, ma anche in questo caso le cose cambiano a seconda della configurazione; sono inoltre supportate su tutte le varianti fino a quattro Thunderbolt 4, due USB 3.2 e otto USB 2.0. Purtroppo Thunderbolt 5 non è integrato, ma potrà essere inserito dai produttori tramite un controller esterno.
Le diverse configurazioni di Panther Lake
Nell'articolo abbiamo parlato più volte della presenza di diverse configurazioni: questo perché, pur non conoscendo i vari modelli specifici, sappiamo che i chip Panther Lake arriveranno in tre varianti.
La prima, quella base, offre una Compute tile con 8 core (4P + 4E) e supporto a memorie LPDDR5X-6800 o DDR5-6400, una Platform Controller tile con 12 linee PCIe (4x Gen 5 e 8x Gen 4) e una GPU tile con 4 core Xe3, che sarà prodotta con processo Intel 3.
La seconda variante integra invece 16 core, suddivisi in 4 P-Core, 4 LPE-Core e 8 E-core, supporta LPDDR5X-8533 e DDR5-7200 e offre 20 linee PCIe (12x Gen 5 e 8x Gen 4). La grafica integrata è la stessa della versione base.
La terza e ultima variante è la più potente: qui troviamo 16 core (4P + 4LPE + 8E), supporto a memorie LPDDR5X-9600, solamente 12 linee PCIe (4x Gen 5 e 8x Gen 4) ma una GPU Tile con 12 core Xe3, prodotta con processo TSMC N3E.
.jpg?width=896 "Clicca per vedere l'immagine originale")
.jpg?width=896 "Clicca per vedere l'immagine originale")
.jpg?width=896 "Clicca per vedere l'immagine originale")
.jpg?width=896 "Clicca per vedere l'immagine originale")
Guardando queste specifiche è facile intuire come la versione base si quella pensata per i dispositivi entry level, che avranno un massimo di 8 core; la seconda è invece adatta a quei device che sfrutteranno una GPU discreta, visto il maggior numero di linee PCIe e i pochi core della grafica integrata, come ad esempio laptop gaming ultrasottili, o notebook per creativi di fascia media; infine, la versione più potente di Panther Lake è progettata per chi ha bisogno di potenza e autonomia e non necessita di una scheda video dedicata, inoltre potrebbe essere molto interessante anche per gli handheld, viste le potenzialità della nuova GPU Xe3.
Per i prodotti bisognerà attendere
Panther Lake converge l’efficienza di Lunar Lake con la scalabilità di Arrow Lake-H dentro una piattaforma estremamente scalabile, pronta per i carichi di lavoro moderni, compresi quelli legati all’intelligenza artificiale. Le premesse sono buone, ma come sempre bisognerà avere il prodotto tra le mani per trarre delle conclusioni reali.

Purtroppo, ci sarà da aspettare: manca ancora qualche mese al lancio dei dispositivi con Panther Lake, che arriveranno verosimilmente in occasione del CES di Las Vegas, previsto per gennaio 2026. Fino ad allora, per avere qualche informazioni in più dovremo accontentarci delle indiscrezioni che emergeranno nel corso dei prossimi mesi.