

Nvidia ha diffuso maggiori informazioni su RC 18, il progetto di ricerca di una soluzione MCM (multi-chip module) scalabile destinato a compiti di inferenza.
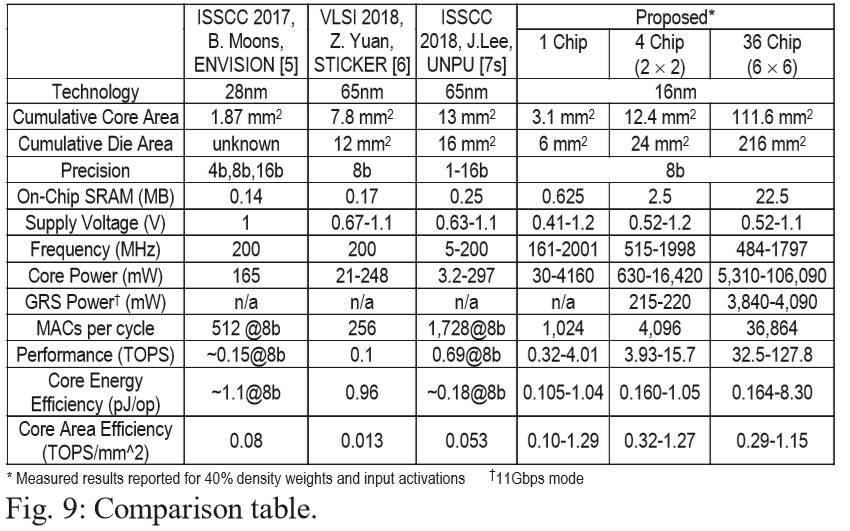
Questo acceleratore di reti neurali profonde (DNN) offre una potenza di calcolo in configurazione a singolo chip di 4,01 TOPS, ma può scalare fino a 36 chip raggiungendo 128 TOPS, e perciò potrebbe trovare collocazione tanto nei dispositivi mobile quanto nei datacenter, perché per ora non è tanto la potenza a colpire, quanto l'efficienza.

Per realizzare il chip Nvidia si è avvalsa del processo produttivo a 16 nanometri, ma chiaramente qualora dovesse arrivare sul mercato potrebbe adottarne uno più avanzato, con un ulteriore miglioramento dei consumi. Ogni singolo chiplet che compone RC 18 occupa appena 6 mm2 e contiene 87 milioni di transistor. Una configurazione MCM con 36 chiplet richiede quindi 216 mm2.
Ogni die ha al suo interno 16 processing elements (PEs) connessi tramite una network-on-chip (NoC), che occupa all'incirca metà area del die. Il resto del die è composto da un router network-on-package (NoP), un buffer generale da 64kB che agisce come archiviazione di secondo livello e un processore di controllo RISC-V.
Secondo una presentazione tenuta da Nvidia al VLSI Symposium 2019, il core di controllo RISC-V configura la comunicazione tra i processing elements (PEs) e i buffer globali tramite registri gestiti via software. Si tratta di un core Rocket con prestazioni comparabili a un ARM Cortex-A5.
I die in configurazione MCM sono connessi in una rete mesh. Laddove il NoC collega i singoli PEs, il router NoP trasferisce i pacchetti tra il NoC e i chip circostanti. Questo avviene grazie a un paio di transricevitori GRS (ground-referenced signaling): ci sono quattro ricevitori e altrettanti trasmettitori, ognuno con una velocità di 100 Gbps.
I GRS assicurano che nessun rumore venga introdotto nell'alimentatore. Il collegamento ha un solo finale, in modo simile alla DisplayPort. Nvidia ha dichiarato di aver lavorato per cinque anni su questo collegamento e pensa che potrebbero usarlo per collegare GPU in un insieme 2x2 su un package con DRAM, ripetendo poi il processo con i package. Una scheda di questo tipo con 16 GPU potrebbe poi essere ulteriormente connessa ad altre schede in una topologia toro.
Per collegare i die Nvidia ha usato un substrato organico standard per l’MCM, a causa dei costi troppo elevati di un interporser. I sei die superiori sono inoltre usati per compiti di I/O con dispositivi esterni.
Ogni PEs (processing elements) contiene otto linee parallele di unità MAC a 8 vie, ognuna con una precisione di 8 bit, comune nell’ambito dell’inferenza. Dato che ci sono 16 PEs, un chip può svolgere 1024 MACs per ciclo. Alla frequenza massima di 2 GHz con una tensione di 1,2 V, raggiunge prestazioni di 4,1 TOPS (una MAC è composta da due operazioni) consumando 4,2 W. La tensione può essere ridotta fino a 0,41 V.
In una configurazione 6x6 formata da 36 die, la frequenza è fissata a 1,8 GHz, ottenendo 128 TOPs a 106 watt. In questa configurazione Nvidia ha raggiunto un punteggio ResNet-50 di 2615 immagini al secondo a 0,85V, che è un valore comparabile a quattro TPU Google di seconda generazione o quattro Tesla V100. L’azienda ha inoltre raggiunto un uso dell’hardware del 75% su AlexNet.