


La rivoluzione dell'intelligenza artificiale sui dispositivi mobili ha raggiunto un nuovo traguardo con l'implementazione di un nuovo modello linguistico vocale completamente autonomo su smartphone. Honor ha superato una delle sfide più complesse del settore tecnologico, riuscendo a integrare capacità di riconoscimento e traduzione vocale multilingue direttamente nel Magic V5, senza alcuna dipendenza dall'infrastruttura cloud. Questo risultato rappresenta un cambio di paradigma che promette di ridefinire gli standard di privacy e performance nei dispositivi consumer.
Il settore della traduzione vocale ha sempre dovuto confrontarsi con un dilemma fondamentale: garantire prestazioni elevate mantenendo la riservatezza dei dati personali. Le soluzioni attualmente dominanti nel mercato si affidano massicciamente ai server cloud per elaborare le conversazioni, creando vulnerabilità significative per informazioni sensibili come chiamate private o discussioni riservate. Alcune alternative tentano di risolvere questa problematica, ma finiscono per sacrificare drasticamente velocità, precisione e efficienza nell'uso della memoria a causa delle limitazioni hardware dei dispositivi mobili.
La validazione scientifica di questa innovazione è arrivata attraverso due ricerche premiate durante INTERSPEECH 2025, la conferenza mondiale più autorevole nel campo dell'elaborazione del linguaggio parlato. Il primo studio, denominato "MFLA: Monotonic Finite Look-ahead Attention for Streaming Speech Recognition", ha risolto la complessa sfida del riconoscimento vocale in streaming con latenza minima e accuratezza massima sui dispositivi. L'approccio rivoluzionario combina un sensore basato su tecnologia CIF (Continuous Integrate-and-Fire) con la strategia Wait-k, superando le limitazioni tradizionali che rendevano difficile l'applicazione diretta di queste tecniche al riconoscimento vocale automatico.
La seconda ricerca, "Novel Parasitic Dual-Scale Modeling for Efficient and Accurate Multilingual Speech Translation", sviluppata in collaborazione con la Shanghai Jiao Tong University, introduce una strategia di accelerazione del campionamento speculativo a doppia scala specificamente progettata per dispositivi con risorse limitate. Questa metodologia permette di aumentare del 38% la velocità di inferenza mantenendo intatte le prestazioni del modello, un risultato che sembrava impossibile fino a poco tempo fa.
L'efficienza che cambia le regole del gioco
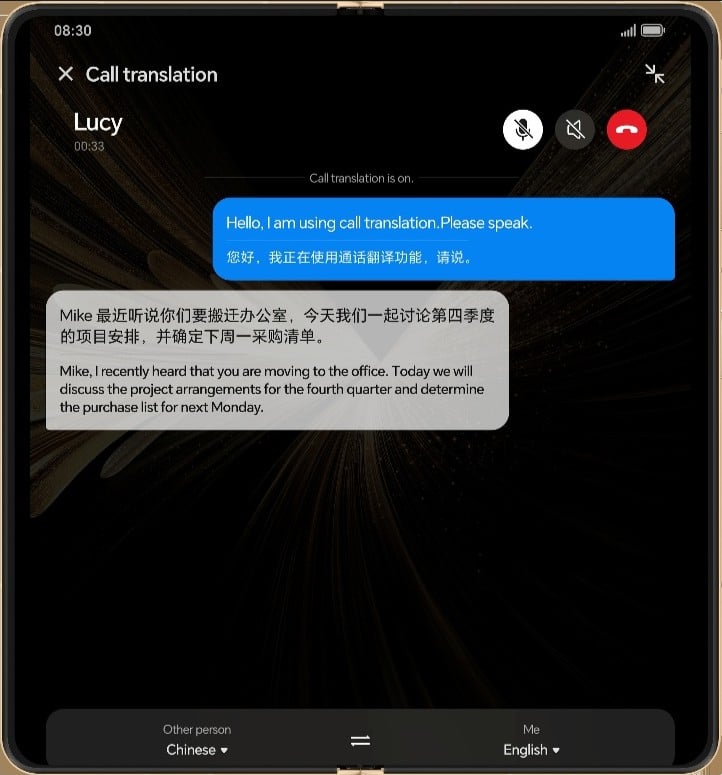
I numeri che emergono dall'implementazione pratica di questa tecnologia sono impressionanti e dimostrano come l'innovazione possa trasformare radicalmente l'esperienza utente. L'ingombro di memoria è stato ridotto in modo drastico, passando dai tradizionali 3-4GB a soli 800MB, ottenendo un risparmio del 75% delle risorse di sistema. Questa ottimizzazione include l'integrazione nativa di sei pacchetti linguistici completi: cinese, inglese, tedesco, francese, spagnolo e italiano.
L'eliminazione della necessità di sei download separati da 500MB ciascuno comporta un ulteriore risparmio di circa 2,78GB di spazio di archiviazione, liberando risorse preziose per altri utilizzi. Ma il vero salto qualitativo si manifesta nella modalità di traduzione "speak-as-you-go", che permette la conversione linguistica istantanea durante la conversazione, senza dover attendere il completamento di intere frasi come richiesto dai metodi tradizionali.
Le prestazioni registrate mostrano un incremento del 38% nella velocità di elaborazione accompagnato da un miglioramento del 16% nell'accuratezza della traduzione. Questi risultati dimostrano che non è più necessario scegliere tra privacy e performance: la tecnologia on-device offre un'esperienza paragonabile alle soluzioni cloud garantendo al contempo la protezione completa delle informazioni personali.
L'innovazione tecnica alla base di questi risultati risiede nell'integrazione di un sistema di predizione basato su meccanismo CIF, che mappa le caratteristiche acustiche continue alle decisioni discrete richieste dalla strategia Wait-k. Questo approccio ha permesso di adattare con successo tecniche a bassa latenza dal dominio testuale a quello vocale, superando i costi computazionali elevati che caratterizzavano le implementazioni precedenti.
L'impatto di questa tecnologia si estende ben oltre le specifiche tecniche, aprendo la strada a interazioni uomo-dispositivo più naturali e sicure. La capacità di elaborare il linguaggio parlato direttamente sul dispositivo elimina la dipendenza dalla connettività di rete e riduce significativamente i tempi di risposta, creando le premesse per una nuova generazione di applicazioni basate sull'intelligenza artificiale distribuita.