



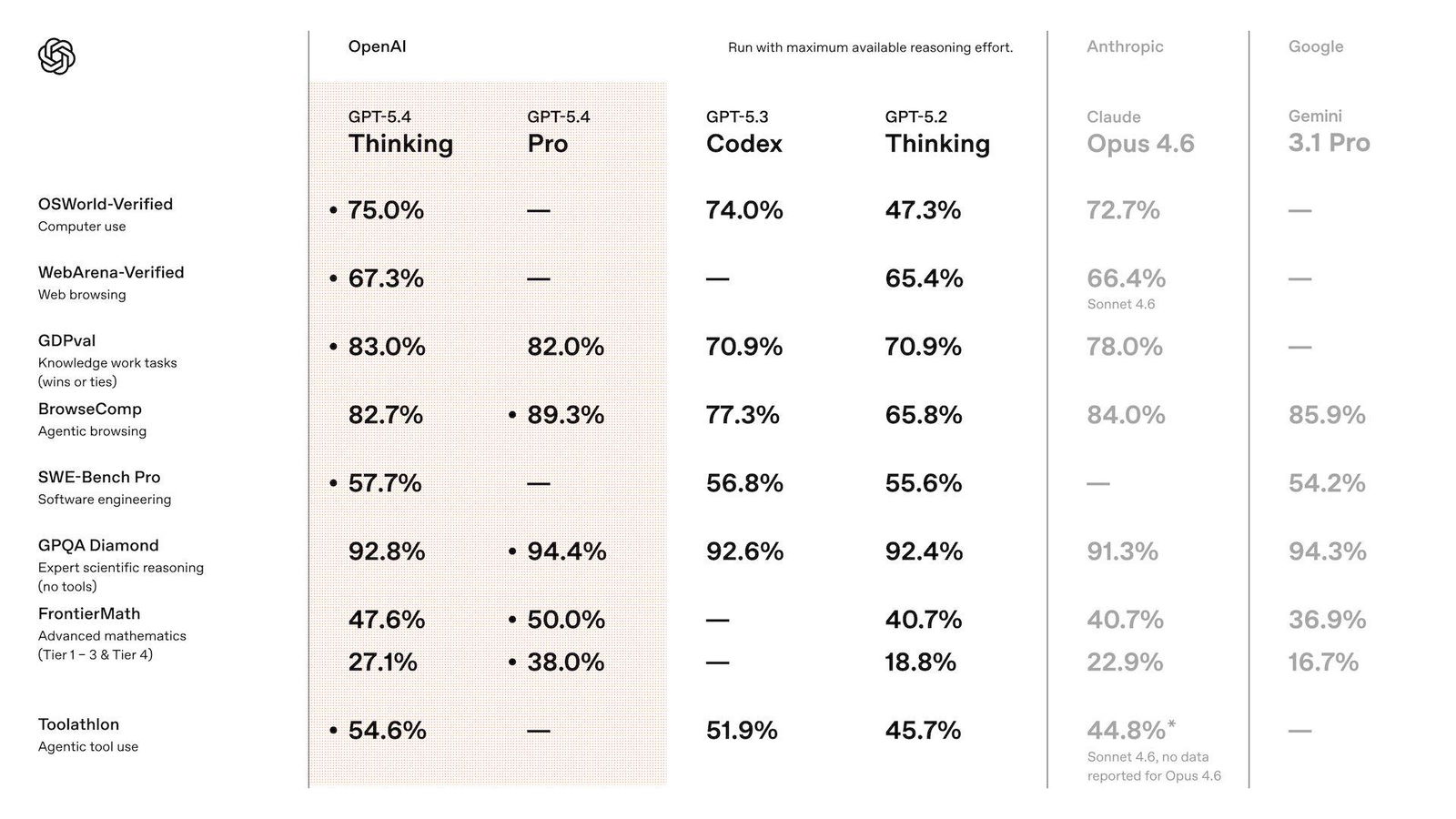
OpenAI ha pubblicato GPT-5.4 il 5 marzo 2026 e il numero che vale la pena citare subito è questo: su OSWorld-Verified, il benchmark che misura la capacità di controllare un computer reale usando screenshot, tastiera e mouse, GPT-5.4 ottiene il 75,0% di successo contro il 72,4% del riferimento umano e il 47,3% del precedente GPT-5.2. Supera di due punti il precedente record di Claude Opus-4.6 .
Quindi questo modello è più efficace dell’essere umano medio in un ambiente desktop. OSWorld-Verified non valuta test sintetici ma operazioni reali su interfacce vere; è l’ennesima soglia di frontiera e chi non ci crede farebbe bene a vederlo all’opera.
Tre versioni, un solo modello di base
OpenAI distribuisce GPT-5.4 in tre configurazioni. La versione Thinking è quella standard: gira su ChatGPT per gli abbonati Plus, Business e Pro, via API con il model string gpt-5.4, e nell'app Codex. Sostituisce GPT-5.2 Thinking e costa $2,50 per milione di token in input e $15 per milione in output, in aumento rispetto ai prezzi di GPT-5.2.

GPT-5.4 Pro punta ai carichi di lavoro estremi: gira solo su ChatGPT (piano Pro a $200/mese ed Enterprise) e via API come gpt-5.4-pro a 30/180 per milione di token. È il modello più caro che OpenAI abbia mai rilasciato, e la differenza sui benchmark rispetto alla versione Thinking non è sempre proporzionale al prezzo: su GDPval entrambe ottengono circa 83%. Il Pro eccelle su matematica avanzata (38% su FrontierMath contro 27,1%) e sulla ricerca web profonda, dove BrowseComp segna 89,3% contro 82,7%.
GPT-5.4 standard, senza suffisso Thinking, resta nell'ecosistema per chi ha bisogno di latenza minima senza ragionamento esteso.
# Confronto flagship LLM (marzo 2026)
1. Confronto diretto tra flagship (marzo 2026)
| Flagship model | Input ($/M tok) | Cached ($/M) | Output ($/M tok) | Batch/Flex ($/M tok) | Priority ($/M tok) | Context standard | Context esteso / note |
|---|---|---|---|---|---|---|---|
| OpenAI GPT‑5.4 (API) | $2.50 | $0.25 | $15 | $1.25 in / $7.50 out | $5 in / $30 out | ~272K | 1M in Codex a 2× costo oltre 272K; maggiore efficienza token |
| OpenAI GPT‑5.4‑pro (API) | $30 | – | $180 | $15 in / $90 out | $60 in / $360 out | ~272K | Pensato per task estremamente complessi e agent “heavy” |
| GPT‑5.4 Thinking (ChatGPT) | – | – | – | – | – | Come GPT‑5.2 Thinking | Stesso context di 5.2 Thinking; 1M solo in Codex sperimentale |
| Gemini 3.1 Pro (≤200K) | $2.00 | $0.20 | $12 | n/d | n/d | 200K+ | Prezzo base fino a 200K, oltre cambia tier |
| Gemini 3.1 Pro (\>200K) | $4.00 | $0.40 | $18 | n/d | n/d | 200K+ | Tier più caro per context lunghi |
| Claude Opus 4.6 | $5.00 | $0.50 | $25 | n/d | n/d | 1M | 1M contesto “nativo”, output molto ampio |
| Claude Sonnet 4.6 (≤200K) | $3.00 | $0.30 | $15 | n/d | n/d | 200K–1M | Tier base fino a 200K |
| Claude Sonnet 4.6 (\>200K) | $6.00 | $0.60 | $22.50 | n/d | n/d | 200K–1M | Tier premium per context esteso |
Note:
- Batch/Flex su GPT‑5.4: metà del prezzo standard (input e output).
- Priority su GPT‑5.4: doppio del prezzo standard (input e output).
- GPT‑5.4 in Codex: supporto sperimentale a 1M di contesto; tutto ciò che supera 272K viene fatturato a 2×.
- GPT‑5.4 Thinking sostituisce GPT‑5.2 Thinking in ChatGPT Plus/Team/Pro
- GPT‑5.2 Thinking resta come Legacy fino al 5 giugno 2026.
2. Varianti GPT‑5.4: prezzi e casi d’uso
| Variante GPT‑5.4 | Dove si usa | Prezzo base | Batch/Flex | Priority | Context | Casi d’uso consigliati |
|---|---|---|---|---|---|---|
| GPT‑5.4 (API) | API / Codex | $2.50 in / $15 out per M token | $1.25 in / $7.50 out | $5 in / $30 out | ~272K (fino a 1M in Codex a 2×) | Backend LLM generico, codegen, agent leggeri, tool‑use standard |
| GPT‑5.4‑pro (API) | API | $30 in / $180 out per M token | $15 in / $90 out | $60 in / $360 out | ~272K | Agent complessi, reasoning multi‑step, orchestrazione workflow critici |
| GPT‑5.4 Thinking | ChatGPT (Plus/Team/Pro, Enterprise) | n/d (incluso nel piano ChatGPT) | – | – | Come GPT‑5.2 Thinking | Uso interattivo, brainstorming profondo, debugging ragionato senza gestione diretta di token e batch |
Note:
- GPT‑5.4 è il primo modello “mainline reasoning” che ingloba le capacità di GPT‑5.3‑codex.
- In Codex, il context 1M è abilitato via
model_context_windowemodel_auto_compact_token_limit; oltre 272K i token vengono tariffati a 2×. - GPT‑5.4‑pro è accessibile solo via API (e GPT‑5.4 Pro in ChatGPT è per piani Pro/Enterprise).
- GPT‑5.4 Thinking sostituisce GPT‑5.2 Thinking nei piani a pagamento, con quest’ultimo che rimane come Legacy per tre mesi.
Il context window da 1 milione di token
Il numero che compare in tutti i titoli è la finestra di contesto da 1 milione di token, che quadruplica il limite di GPT-5.2 fermo a 400.000. In pratica, 1 milione di token corrisponde a circa 750.000 parole: puoi caricare una codebase completa, un anno di email aziendali, decine di documenti legali, tutto insieme, nello stesso prompt, senza scegliere cosa troncare.

Ci sono però alcune cose importanti da sapere prima di entusiasmarsi. Il contesto esteso funziona in opt-in: di default il modello lavora su una finestra da 272.000 token, e per salire a 1 milione devi configurare esplicitamente model_context_window e model_auto_compact_token_limit nella richiesta API. Senza questi parametri, resti sul contesto standard.
Oltre i 272K token il costo raddoppia. OpenAI fattura al doppio il costo per token in input e 1,5x per l'output, per l'intera sessione. Non è un dettaglio marginale se stai costruendo pipeline agentiche con contesti molto lunghi, e vale la pena calcolare i numeri prima di abilitarlo in produzione. L’approccio è lo stesso preso da Anthropic, che ha offerto contesti da un milione di token per Sonnet e Opus ma li fa pagare un extra.
OpenAI ha integrato quello che chiama native compaction support: come succede già con i modelli di Anthropic, durante sessioni lunghe il modello comprime il contesto per mantenere coerenza senza perdere le informazioni critiche degli step precedenti.
L’uso del computer diventa nativo
Fino a ieri, fare computer use con OpenAI richiedeva un modello separato, un layer di astrazione, integrazioni specifiche. Con GPT-5.4 il modello general-purpose principale porta questa capacità dentro di sé e la gestisce in due modalità distinte.
La prima è via Playwright: il modello genera codice per automatizzare browser e applicazioni, utile per scraping, test automatici, compilazione di form e interazione con interfacce web che non espongono API. La seconda usa screenshot più mouse e tastiera: il modello riceve uno screenshot dell'interfaccia, poi invia comandi di click e digitazione in risposta, e funziona su qualsiasi applicazione desktop, anche quelle senza documentazione pubblica.
Gli sviluppatori possono configurare il computer tool nell'API tramite developer messages, modulando il comportamento per use case specifici. OpenAI ha introdotto le custom confirmation policies: puoi definire diversi livelli di tolleranza al rischio per operazioni automatizzate, con policy più permissive per agenti che gestiscono file e più restrittive per quelli che accedono a sistemi sensibili.
Un avvertimento concreto emerso dai primi test: GPT-5.4 a volte completa task in modo errato senza segnalarlo chiaramente. Su workflow ad alto rischio devi ancora verificare l'output a mano, e non è un difetto insolito in questa categoria di modelli, ma vale saperlo prima di mandare in produzione.
Sam Altman su X ha già dichiarato che stanno lavorando al fix.
Tool Search: la feature che cambia le pipeline agentiche

Questa è probabilmente la novità più rilevante per chi lavora con sistemi agentici complessi, anche se fa meno sensazione del computer use, probabilmente perché è più difficile da mostrare in un video. In produzione conta di più.
Il problema di fondo: quando costruisci un agente con decine o centinaia di tool disponibili, pensa a server MCP con 30, 50, 100 funzioni, il metodo tradizionale carica le definizioni di tutti i tool nel contesto ad ogni richiesta. Con GPT-5.2 e precedenti questo bruciava decine di migliaia di token ad ogni singola chiamata API, indipendentemente dal fatto che l'agente usasse poi effettivamente quei tool o no.
GPT-5.4 introduce Tool Search: il modello riceve una lista leggera dei tool disponibili invece delle definizioni complete e, quando ha bisogno di usare un tool specifico, lo cerca e carica la definizione completa solo in quel momento, solo per quella operazione. OpenAI ha testato questo sistema su 250 task dello Scale MCP Atlas benchmark con 36 server MCP attivi contemporaneamente e ha ottenuto il 47% di riduzione del consumo token totale con identica accuratezza.
Il 47% è specifico a quel benchmark con 36 MCP server, non un dato generico su tutti i task. Su pipeline più semplici il guadagno sarà diverso, ma per chi gestisce ecosistemi tool complessi è una riduzione concreta sia di costo che di latenza.
Tool Search gira in due modalità:
- hosted search, dove i tool candidati sono noti al momento della richiesta e OpenAI gestisce il lookup
- client-executed search, dove l'applicazione decide dinamicamente quali tool caricare.
Per chi usa già MCP server in produzione o sta costruendo agenti con grandi librerie di funzioni, abilitare Tool Search è la prima cosa da fare dopo la migrazione a GPT-5.4.
I benchmark professionali
GDPval misura la performance su task di knowledge work reale: non problemi accademici, ma deliverable professionali in 44 occupazioni dei 9 settori che contribuiscono maggiormente al PIL americano, dalle sales presentation ai fogli di calcolo contabili alle analisi legali.
In questo test, GPT-5.4 eguaglia o supera il professionista umano nell'83,0% dei confronti, contro il 70,9% di GPT-5.2. Claude Opus 4.6, per riferimento, si ferma al 79,5%.
Su spreadsheet modeling, su un benchmark interno di task da analista junior di investment banking, GPT-5.4 ottiene l'87,5% contro il 68,4% di GPT-5.2, un salto di 19 punti percentuali su un task specifico e misurabile. Sulle presentazioni, i valutatori umani hanno preferito quelle di GPT-5.4 il 68% delle volte rispetto a quelle di GPT-5.2, per estetica, varietà visiva e uso delle immagini generate.
BrowseComp misura la capacità di navigazione web persistente per trovare informazioni difficili da localizzare: GPT-5.4 Thinking arriva all'82,7% con un guadagno di 17 punti su GPT-5.2, mentre GPT-5.4 Pro tocca l'89,3%.
Sulle allucinazioni, le singole affermazioni fattuali hanno il 33% in meno di probabilità di essere false rispetto a GPT-5.2, e le risposte complete sbagliano il 18% in meno. Queste cifre vengono da OpenAI e confrontano GPT-5.4 con GPT-5.2 piuttosto che con il più recente GPT-5.3, dettaglio da tenere a mente nel leggere i numeri.
Su APEX-Agents di Mercor, benchmark per lavoro professionale prolungato in investment banking, consulenza e diritto aziendale, GPT-5.4 guida la classifica. Brendan Foody, CEO di Mercor, lo descrive come il miglior modello provato finora, particolarmente adatto alla produzione di deliverable a lungo orizzonte come slide, modelli finanziari e analisi legali.
La nuova interfaccia di pensiero
GPT-5.4 Thinking mostra il piano di ragionamento prima di iniziare la risposta, e puoi interrompere, correggere, ridirigere senza dover ripartire da zero. Esempio pratico: il modello sta pianificando un'analisi in cinque sezioni, vedi il piano, ti accorgi che la terza sezione non ti serve, scrivi "salta la parte su X, concentrati su Y" e il modello riorienta il ragionamento senza sprecare un turno completo di conversazione. Per task lunghi e complessi questo taglia il numero di iterazioni necessarie per arrivare all'output finale.
GPT-5.4 e il coding
GPT-5.4 assorbe le capacità di GPT-5.3-Codex e su SWE-Bench Pro, che misura la risoluzione di issue reali da repository GitHub, lo eguaglia o supera pur aggiungendo computer use e Tool Search. Nell'app Codex, la modalità /fast porta fino a 1,5x di velocità nel token output rispetto alla modalità standard, con la stessa intelligenza. Via API ottieni la stessa velocità usando Priority processing.
Su Toolathlon, benchmark che misura la capacità di usare tool e API reali in task multi-step come leggere email, estrarre allegati, caricarli, valutarli e registrare risultati in un foglio di calcolo, GPT-5.4 supera GPT-5.2 in accuratezza con meno "tool yield", cioè meno cicli di attesa per le risposte dei tool. Il parallelismo nelle chiamate migliora il throughput effettivo.
Per chi usa OpenClaw
OpenClaw è la piattaforma agentica su cui una parte crescente dei power user costruisce workflow autonomi. Il team di Every, che la usa come daily driver per lo sviluppo software, ha fatto un live stream di vibe check il giorno del lancio, e il giudizio è diretto: GPT-5.4 è best in class nel planning, con piani tecnici e dettagliati ma con un tono sorprendentemente leggibile. Le trace di pensiero sono trasparenti e il modello gira veloce.
I primi utenti hanno segnalato due problemi. Il modello tende all'overbuilding: a volte costruisce più di quanto richiesto, aggiunge feature non specificate e si allarga sullo scope senza che tu l'abbia chiesto. Su OpenClaw ha anche prodotto output errati senza segnalarli chiaramente in alcuni test, comportamento non raro nei modelli più potenti che completano i task con più autonomia e meno cautela nei casi borderline. La pratica consigliata è aggiungere step di verifica espliciti nel workflow per task ad alto rischio, senza lasciare che GPT-5.4 proceda da solo su operazioni irreversibili.
Sul fronte Tool Search, OpenClaw gestisce già server MCP multipli e con questa funzione il carico di token per sessione cala in modo significativo. Chi ha già ottimizzato manualmente i propri skill set con tool come OpenClaw Token Optimizer, che fa lazy loading dinamico, ritrova ora questa logica dentro il modello senza patch esterne.
Sul contesto da 1M, ha senso per task che gestiscono codebase molto grandi, cronologie di conversazione lunghissime o documenti voluminosi. Per i task standard il contesto da 272K basta già, e vale la pena calcolare il costo prima di abilitare il contesto esteso su pipeline in produzione, perché il raddoppio della fattura oltre la soglia può fare male.
GPT-5.4 supporta cinque livelli di reasoning effort: none, low, medium, high e xhigh, con none come default. Per task di planning complesso in OpenClaw, high o xhigh danno risultati nettamente migliori. Temperature, top\_p e logprobs funzionano solo al livello none: se hai bisogno di controllo fine sui parametri di campionamento, sei vincolato a quel setting.
La sicurezza del chain of thought
OpenAI ha introdotto in GPT-5.4 una nuova valutazione per testare l'onestà del ragionamento durante task multi-step. Il problema era noto: i modelli di reasoning potrebbero, in teoria, eseguire ragionamenti interni che non corrispondono a quelli che mostrano all'utente. I test indicano che GPT-5.4 Thinking è meno incline a questo tipo di disallineamento rispetto ai predecessori, con un chain of thought visibile che corrisponde meglio al ragionamento effettivo. Non è ancora una garanzia assoluta, ma è un passo verso modelli agentici in cui la trasparenza del pensiero risulta verificabile e non solo dichiarata.
Durante i task agentici, GPT-5.4 preserva il 53% del lavoro già esistente dell'utente, contro il 18% di GPT-5.2-Codex: l'agente è più cauto nel sovrascrivere o modificare ciò che trovava già presente.
Disponibilità e pricing
| Versione | Disponibile in | Costo input | Costo output |
|---|---|---|---|
| GPT-5.4 Thinking | ChatGPT Plus/Team/Pro, API (gpt-5.4), Codex | $2,50/1M token | $15/1M token |
| GPT-5.4 Pro | ChatGPT Pro/Enterprise, API (gpt-5.4-pro) | $30/1M token | $180/1M token |
| Batch/Flex | API | Metà prezzo standard | Metà prezzo standard |
| Priority | API | Doppio prezzo standard | Doppio prezzo standard |
Superare i 272K token in input attiva il 2x sul costo per token per l'intera sessione, e non è un dettaglio piccolo su pipeline con contesti lunghi. Il contesto da 1M gira in API e Codex come opt-in via parametro, di default il modello non lo attiva, e ChatGPT usa il contesto standard.
OpenAI ha anche annunciato un'integrazione beta di GPT-5.4 direttamente in Excel e Google Sheets, con accesso a dati di FactSet, MSCI, Third Bridge e Moody's. Per ora tocca solo i clienti Enterprise e include "Skills" riutilizzabili per analisi ricorrenti come earnings preview, comparables analysis, DCF e investment memo.
Chi dovrebbe fare cosa adesso
L'utente ChatGPT generico deve solo aggiornare a GPT-5.4 Thinking dal selettore del modello. Lo sviluppatore API migra da gpt-5.2 a gpt-5.4, ma conviene rivedere i prompt di sistema prima perché il modello è più autonomo e può interpretare istruzioni ambigue in modo diverso. Meglio testare su un campione di task prima del rollout completo.
Chi usa MCP server abilita Tool Search e configura i server dietro il layer dedicato invece di esporre le definizioni direttamente nel contesto.
Chi usa OpenClaw adotta GPT-5.4 per task di planning e review, aggiunge step di verifica espliciti per operazioni ad alto impatto e valuta il contesto esteso solo se i task richiedono davvero oltre 272K token.
Chi sta valutando GPT-5.4 Pro tenga presente che ha senso principalmente per matematica avanzata e ricerca web profonda: su knowledge work professionale standard la versione Thinking porta già all'83% su GDPval, e il Pro aggiunge valore marginale a un costo sei volte superiore.
Il punto
GPT-5.4 è il modello che più di qualsiasi altro prima d'ora giustifica la parola "agentico" nel senso stretto: agisce. Il computer use nativo, il Tool Search che taglia del 47% il consumo token su ecosistemi MCP complessi e il contesto da 1 milione di token sono tre pezzi che si connettono verso la stessa direzione, quella di agenti che fanno lavoro reale in autonomia su orizzonti temporali lunghi, senza diventare impossibili da gestire per costi o latenza.
Non è ancora il sistema che non richiede supervisione. I falsi negativi esistono e su operazioni irreversibili devi ancora tenere un occhio umano. Ma chi lavora già con piattaforme agentiche come OpenClaw ha adesso un modello che ha fatto un passo avanti concreto, e chi non ha ancora valutato questi workflow probabilmente dovrebbe farlo.
GPT-5.4 gira da oggi su ChatGPT per gli abbonati Plus, Team e Pro. Gli sviluppatori OpenAI possono accedere all'API tramite gpt-5.4 e gpt-5.4-pro. La documentazione ufficiale è su openai.com.




