


Emulare il cervello umano con un computer per creare delle intelligenze artificiali superiori, è questo lo scopo, espresso in poche parole, dell’informatica e dei chip neuromorfici. Gli amanti della fantascienza staranno già pensando a Skynet (Terminator) e alla conseguente fine del mondo e dominio delle macchine, ma nonostante l’obiettivo di questa branca della scienza sia proprio quello indicato (le IA superiore, non la fine del Mondo!) siamo ancora molto lontani da automi in grado di pensare come gli esseri umani. Il motivo principale è presto spiegato: nonostante le ricerche e scoperte da premio Nobel di questi ultimi decenni, oggi conosciamo ancora molto poco del nostro cervello e il modo in cui funziona, sarebbe quindi piuttosto pretenzioso pretendere di realizzare un computer che funzioni come qualcosa di cui conosciamo ancora poco o niente. Nonostante ciò i chip e l’informatica neuromorfica sono qualcosa di reale, esistono soluzioni e processori che ne fanno uso ed è già utilizzata in diversi ambiti. Esistono soluzioni sperimentali di ricerca e anche prodotti finali, ma nulla che si possa acquistare su Amazon e riceverlo in un giorno, per essere chiari. Nessuno può dire se questo “nuovo” approccio all’informatica sostituirà le CPU per come le conosciamo oggi, ma in ambito scientifico e di ricerca vengono già ampiamente usati.

Perché ricostruire il cervello umano?
Il cervello umano è un computer estremamente potente ed enormemente efficiente. Nel nostro cervello ci sono approssimativamente 86 miliardi di neuroni connessi tra loro da 1015 sinapsi, un numero difficilmente immaginabile. Se volessimo sommare la lunghezza di queste connessioni, presenti in un volume pari a un millimetro cubo del nostro cervello (della corteccia, dove è presente la maggior parte dei neuroni / sinapsi), raggiungeremmo lunghezze espresse in chilometri di connessioni. Il nostro cervello, in termini di complessità, è qualcosa di inimmaginabile, e tutta questa complessità ci permette di ottenere delle potenze di calcolo nemmeno lontanamente avvicinabili dai computer moderni.
Le azioni che svolgiamo quotidianamente sono per noi talmente basilari e banali che non ci rendiamo conto della potenza di calcolo che sarebbe necessaria per riprodurle con un computer: quando ci guardiamo attorno e percepiamo l’ambiente che ci circonda e la nostra presenza in esso, riceviamo un quantitativo enorme di informazioni sotto forma di luce sulle varie frequenze, calcoliamo queste informazioni e le trasformiamo nelle immagini in movimento che percepiamo, calcoliamo la nostra posizione in un ambiente tridimensionale e tutto questo contemporaneamente ad altre elaborazioni dati, quelli che ci permettono di percepire le variazioni di temperatura, di stare in equilibrio, quelle riguardanti i suoni e molte altre. Realisticamente anche quando stiamo fermi, senza fare nulla, in realtà stiamo elaborando un sacco di informazioni esterne e interne al nostro corpo. Sapete quanta energia consuma il nostro cervello per fare tutti questi calcoli ? Il corrispettivo di circa 20 watt, un valore molto inferiore rispetto a quello dei processori moderni che sono in grado di raggiungere solo una minima frazione delle prestazioni del nostro cervello.
Ecco perché si vuole costruire un sistema in grado di imitare il comportamento del cervello: elevate prestazioni di calcolo e, soprattutto, consumo energetico bassissimo. In altre parole l’obiettivo è quello di ottenere altissima efficienza.
Addio Von Neumann
Tutti i computer moderni sono realizzati seguendo quella che viene definita “Architettura di Von Neumann”, che prevede una netta separazione tra la parte del computer adibita ai calcoli, cioè la CPU, e la memoria, cioè dove vengono immagazzinati i dati da utilizzare e i risultati dei calcoli effettuati. Questo approccio è usato da decenni e i processori moderni, nonché i software, sono sviluppati per funzionare con questa logica. Un vantaggio di questa soluzione, possiamo dire con il senno di poi, è stata la possibilità di sviluppare tecnologia facilmente adattabile al passare dei tempi e compatibile con gli elementi tecnologici disponibili durante l’evoluzione del settore. Insomma, un approccio che ha permesso di adattarsi alle tecnologie e i loro costi, rompendo barriere tecniche più o meno sfidanti che, per nostra fortuna, non ha posto un freno allo sviluppo. Questo approccio ha però degli svantaggi: la necessità dei dati di viaggiare avanti e indietro tra i differenti componenti limita le prestazioni (dopotutto il tempo usato per trasportare le operazioni rappresenta un ritardo sul tempo in cui è possibile portare a termine i calcoli, quindi le prestazioni calcolate nell’unità di tempo sono inferiori) e consuma energia, un sacco di energia considerando che la quantità di informazioni che devono essere trasportare all’interno di un computer moderno sono tantissime.
Con l’obiettivo di realizzare un sistema che possa essere anche molto efficiente, come indicato nel capitolo precedente, era necessario abbandonare l’approccio Von Neumann per qualcosa di più “economico” in termini di necessità energetiche, e la soluzione adottata nell’approccio neuromorfico è la creazione di nodi computazionali che possano già possedere tutto il necessario per elaborazione e memorizzazione dati. In termini pratici un chip neuromorfico abbina l’unità computazionale e la memoria, tutto in un unico posto, non solo per le questioni di efficienza già espresse, ma anche perché non sarebbe possibile fare interagire i singoli nodi computazionali, i “neuroni artificiali”, tra loro senza che ognuno possa avere a disposizione una soluzione di memorizzazione propria.
Questo non significa che un chip o un computer neuromorfico non abbia, da qualche parte all’interno del suo sistema, una memoria di supporto esterna e degli hard disk. In effetti ci sono, ma quello che cambia è il modo in cui viene gestita la logica dei calcoli e delle informazioni. Molto meno lineare rispetto a quella dei computer moderni e molto più dislocata in varie zone del chip.

L’ulteriore differenza dei sistemi neuromorfici rispetto alle CPU attuali è l’uso di un linguaggio analogico, non binario. La scelta del digitale per i computer, quindi l’uso del linguaggio binario composto da 1 e 0 (da soluzioni con solo due stati) è stata una scelta di necessità. Bisognava trovare un modo semplice per rappresentare dei dati e farli interagire tra loro sfruttando la tecnologia esistente - una tecnologia che si potesse controllare e riprodurre facilmente. Due soli stati sono facili da ottenere in elettronica (una differenza di tensione è facile da misurare e gestire, in altre parole), ma questo approccio è troppo semplicistico per essere adottato in una soluzione neuromorfica, poiché il nostro cervello, i nostri neuroni, non sono “accesi o spenti”, bensì comunicano tra loro con differenti livelli di attivazione e in base a questi livelli si possono classificare le informazioni e la loro importanza.
Cerchiamo di capire meglio con un esempio. Nel nostro cervello ci sono un sacco di neuroni, collegati tra loro da un numero altissimo di dendriti che hanno lo scopo di ricevere le informazioni dagli altri neuroni (con il termine “sinapse” si identifica la terminazione di collegamento tra due cellule nervose, quindi è possibile anche dire che i neuroni sono collegati tra loro da tantissime sinapsi). Una volta che le informazioni sono state ricevute, queste vengono elaborate dal neurone che poi invia il “risultato” della sua elaborazione tramite l’assone, che è il dendrite adibito al rilascio dell’informazione. Altri neuroni prendono a loro volta questa informazione, la elaborano e rilasciano il risultato della loro elaborazione, e questa operazione avviene in maniera costante e continua in tutto il nostro cervello. Tuttavia questo non significa che i nostri neuroni accettano ed elaborano tutte le informazioni con la stessa importanza, bensì “pesano” il tipo di informazione per dargli più o meno importanza.
Facciamo un esempio. In questo momento voi state leggendo questo testo, e ciò significa che i vostri neuroni stanno ricevendo informazioni dalla retina dei vostri occhi, le stanno elaborando per permettervi di comprendere le forme di queste lettere, che a loro volta vengono elaborate in parole per darle un significato e, infine, state elaborando quel significato per comprendere il messaggio e le informazioni in esse contenute. In realtà in questo momento il vostro cervello è bombardato da molte altre informazioni, perché i vostri occhi stanno vedendo anche altro, come la cornice dello schermo del vostro computer, l’ambiente in cui siete immersi, le vostre orecchie stanno sentendo dei rumori, il vostro corpo vi comunica varie informazioni tattili, olfattive, magari vi brontola la pancia perché avete fame o il vostro “sedere” vi sta dicendo che dovete cambiare posizione perché inizia ad essere scomodo. Ma in questo momento non tutte queste informazioni hanno la stessa importanza, perché siete concentrati a leggere questo testo, quindi tutte le altre informazioni hanno un peso, un’importanza, minore.
I neuroni del vostro cervello che stanno ricevendo le informazioni riguardanti la lettura di questo testo creano delle connessioni più solide con gli altri neuroni che condividono le stesse informazioni, mentre tutti i canali di comunicazione che stanno portando altre informazioni meno importanti sono ora in secondo piano, quindi le connessioni sono più deboli. Se questo meccanismo non accadesse, allora il nostro cervello sarebbe costantemente travolto da una quantità d’informazioni tale che probabilmente vi farebbe impazzire.
Per riprodurre questo comportamento in un chip neuromorfico è necessario utilizzare un metodo di comunicazione analogico, proprio come avviene nel nostro cervello (i neuroni non sono accesi o spenti, l’informazione non è “importante” o “non importante”, bensì le informazioni sono tra loro più o meno importanti, con vari livelli di importanza). I neuroni gestiscono queste comunicazioni grazie ai neurotrasmettitori, delle sostanze chimiche che in base alla loro quantità vanno a definire il comportamento appena spiegato. Laddove l’informazione ha un peso maggiore, quindi è più importante, maggiore sarà la quantità di neurotrasmettitori. Tornando nuovamente all’esempio di quello che vi sta succedendo in questo momento, i legami che portano le informazioni sulla lettura di questo testo sono molto importanti, quindi hanno un peso alto, probabilmente le informazioni riguardanti la cornice del monitor su cui state leggendo questo testo sono poco importanti, quindi i vostri neuroni stanno dando pochissima priorità (peso) a questa informazione, mentre l’informazione del vostro stomaco che brontola e che vi comunica che dovete mangiare avrà un peso superiore alla cornice del monitor, ma inferiore rispetto alla lettura di questo testo perché vi sta entusiasmando (vero?), e quindi il vostro stomaco può attendere.
Per gestire questi differenti livelli di dati l’informatica binaria non basta (1 e 0, in questo caso “importante” o “non importante”), di conseguenza l’hardware adottato per la realizzazione dei computer neuromorfici deve essere in grado di registrare ed elaborare più livelli di informazioni (motivo per cui vengono definiti analogici e non digitali), e di conseguenza anche i software devono essere differenti.
In realtà è possibile emulare dei dati analogici sfruttando sistemi digitali (e viene fatto tutt’ora per gestire dati complessi), ma ciò comporta la necessità di realizzare sovrastrutture e relazioni gerarchiche tra i dati che porterebbe l’hardware moderno, già inefficiente di suo per un uso di questo tipo, ad essere ulteriormente peggiore. Quando si cerca di emulare questo comportamento tramite il software, la situazione non è migliore, poiché essendo l’hardware digitale, sono necessari molti calcoli aggiuntivi per simulare un comportamento analogico.
Il principio base
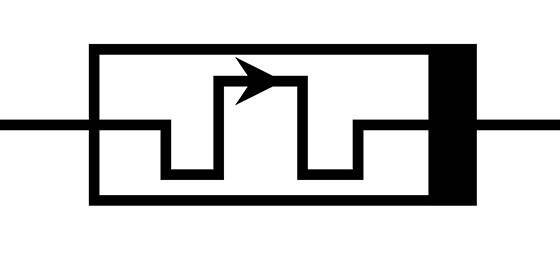
Se abbiamo capito il principio di funzionamento del nostro cervello, è chiaro che i ricercatori e ingegneri che realizzano chip e sistemi neuromorfici utilizzano componenti elettronici in grado di rilevare e scambiare informazioni che hanno differenti “intensità”, quindi non più solo 0 e 1, ma molti più dati. Per fare ciò le tecniche adottate e quelle che si stanno sperimentando sono molte, ma dedichiamo un piccolo approfondimento a uno dei componenti che viene spesso citato, e cioè il MemResistor. Dopo aver capito di cosa si tratta, dovremmo essere in grado di capire meglio quanto espresso nei capitoli precedenti e come si passa dalla teoria alla pratica, cioè come è possibile emulare il comportamento del cervello su un dispositivo elettronico.
Questo componente elettronico è stato teorizzato nel 1971, e ci sono voluti 37 anni (2008) prima che venisse realizzato veramente. Per spiegare correttamente il funzionamento sarebbe necessario un approfondimento a parte, quindi “banalizziamo” il concetto in questa maniera. Un transistor è una sorta di interruttore che cambia il suo stato quando interessato da una corrente elettrica (scritto così è scorretto, ma accettiamo questa descrizione per il nostro fine divulgativo). Quindi la presenza o meno di corrente definisce lo stato di “acceso o spento”, che sono gli stadi 1 e 0 dell’informatica binaria. Un MemResistor può cambiare il suo stato in base all’intensità della corrente che lo attraversa, e “ricordarsi” quel suo stato quando non c’è più corrente. In questa maniera non assume solo lo stato di “acceso o spento”, bensì molti stati, che potete facilmente immaginare come dei numeri o delle percentuali. Più la corrente è intensa, più il numero è alto.
Prima abbiamo detto che i neuroni del nostro cervello classificano le informazioni in più o meno importanti (pesi più alti o più bassi) e creano delle connessioni più solide con i neuroni che considerano importanti lo stesso tipo di informazioni. Ma come un neurone decide che quell’informazione (la lettura di questo testo) è più importante rispetto a un’altra (il colore della cornice del monitor su cui stiamo leggendo)? La risposta più semplice, ma in realtà anche corretta, è “lo fa in base alla quantità di informazioni simili ricevute” (correlazione spaziale, ne parleremo ulteriormente fra poco). Come scritto precedentemente, in questo momento i neuroni del nostro cervello stanno ricevendo un sacco d’informazioni: tutto quello che i nostri occhi vedono, le nostre orecchie sentono, le nostre mani toccano e i nostri organi interni stanno facendo. Ma dato che siamo concentrati su questo testo, molti neuroni che hanno ricevuto le “informazioni visive” dai nostri occhi stanno rilasciando, come risultato dell’elaborazione di queste informazioni, un’informazione (un dato) riguardo a questo testo (perché ovviamente siamo concentrati sulla lettura di questo articolo). In questo modo i legami con i neuroni che stanno rilasciando informazioni differenti saranno più deboli, e quelle informazioni saranno considerate meno importanti. Se continuerete a leggere questo testo all’ora di cena, probabilmente a un certo punto la maggior parte dei vostri neuroni inizierà a dare più importanza allo stimolo della fame, e finirete con abbandonare la lettura e, in questo caso, vi auguro buon appetito.
Ribadito il concetto di funzionamento con questi esempi, immaginiamo ora un processore neuromorfico. Al suo interno sono presenti migliaia di neuroni artificiali (quindi unità di elaborazione con la propria memoria, come un MemResistor) che vengono stimolati, cioè gli vengono passati degli stimoli sotto forma di dati, di informazioni. Ovviamente questi “neuroni artificiali” sono tutti connessi tra loro, come accade nel cervello. Ogni “neurone artificiale” riceve questi dati e li elabora, e rilascia agli altri neuroni (MemResistor) un risultato (dei dati). Questi dati vengono presi da tutti gli altri neuroni e s’innesca questa elaborazione continua come accade nel nostro cervello. I dati che rilasciano sono differenti, ma appena accade che inizia a prevalere un certo tipo di risultato (di dato) allora i pesi iniziano a cambiare, quindi i MemResistor aumentano il loro potenziale (ricordate che possono assumere differenti livelli, non solo 1 e 0) e quel tipo di risultato inizia a guadagnare maggiore importanza. Il computer con questo processo sta “ragionando” e sta “facendo delle scelte”, perché dalla grande quantità di dati grezzi sta elaborando e pesando i risultati.
A questo punto potrebbe esserci un po’ confusi, quindi è necessario specificare che sistemi di questo tipo vedono la loro applicazione in intelligenze artificiali. Cioè, il tipo di dato e azione che viene dato in pasto a un sistema neuromorfico non è del tipo “ti do due numeri e devi farmi la somma”, piuttosto è del tipo decisionale complesso e astratto, ad esempio “ti do un’immagine e devi dirmi che cosa rappresenta”. Immaginate un bambino, con un cervello molto giovane, che vede per la prima volta una mela. Probabilmente voi direte a quel bambino che si tratta di un frutto, che il frutto si può mangiare, che esistono molti tipi di frutta, di diversi colori, forme e dimensioni. A quel punto il bambino avrà abbastanza informazioni per riconoscere una mela, e probabilmente quando vedrà altri frutti saprà riconoscerli come tali, anche se non li ha mai visti primi. Probabilmente quando vedrà un’arancia il suo cervello gli dirà che “forse è un frutto”, anche se non l’ha mai vista prima e non sa come si chiama. Considerando le informazioni immagazzinate in passato (l’esperienza con la mela), alcuni neuroni gli diranno “assomiglia alla mela, ha un colore e una forma diversa, ma potrebbe essere un frutto” e altri neuroni gli diranno “è una palla, ma più piccola”. Probabilmente la maggior parte dei neuroni dirà che si tratta di un frutto perché riconosceranno più similarità con la mela anziché con la palla, e di conseguenza il bambino avrà la convinzione di essere davanti a un frutto e non ha una piccola palla (ricordate il funzionamento, i neuroni aumentano il peso delle loro connessioni e quindi quell’informazione ha un’importanza superiore).
Lo stesso accade all’interno del nostro chip neuromorfico. Alcune unità “vedranno” la foto dell’arancia e il risultato dell’elaborazione dati sarà “è un frutto”, e siccome la maggior parte dei “neuroni artificiali” rilascerà il risultato “è un frutto”, allora il computer neuromorfico comunicherà al suo utilizzatore “nell’immagine qui rappresentata c’è un frutto”. Ovviamente questo è un esempio banale (non servono i chip neuromorfici per algoritmi di IA in grado di riconoscere un’immagine), ma in reali applicazioni, sfruttando questo sistema, sarà possibile chiedere ai computer neuromorfici di fare “ragionamenti” più complessi, gli stessi che facciamo noi umani quando siamo di fronte a un problema da risolvere. Se non conosciamo la soluzione a quel problema, quello che fa il nostro cervello è usare delle informazioni che possiede e capire come queste informazioni possono portare a una soluzione. Tutte le informazioni che possiede sono quelle immagazzinate negli anni e nelle esperienze.
Un computer neuromorfico, avendo la struttura in grado di elaborare i dati, dare un’importanza differente al tipo di risultato dell’elaborazione per giungere alla soluzione più consona, può arrivare al punto di ragionare come un cervello. Ovviamente quello che deve avere è un insegnamento di base, cioè un sistema neuromorfico deve essere alimentato da dati e deve essere qualcuno (o qualcosa) che gli dice se i “ragionamenti” che sta facendo sono giusti o sbagliati (cioè se i dati risultanti delle elaborazioni sono corretti o sbagliati). Questo è imprescindibile. Se date una mela al bambino, senza spiegargli che è un frutto e che si deve mangiare, lui potrebbe reagire, ad esempio, lanciandola come se fosse un gioco, o annusandola e morsicandola (o in un sacco di altre maniere). Starà a noi, in questo caso, dire al bambino “non devi lanciarla, non è un gioco” e lasciare che poi provi qualcos’altro. E lo stesso dovremo dire al computer “no, non è un giocattolo” e lasciare che in base alle informazioni che possiede provi a dare come risultato qualcos’altro, fino a quando gli diremo “si, è un frutto e si può mangiare”. Si tratta semplicemente dell’apprendimento, un processo in cui si usano le informazioni che si hanno per ottenerne di altre, più complesse. E la fase dell’apprendimento deve essere seguita da dei controlli o situazioni che ci dicono cosa è giusto o sbagliato, o meglio cosa è corretto e scorretto. In entrambi i casi (giusto o sbagliato) il nostro cervello sta immagazzinando nuove informazioni che potranno essere usate in altri ragionamenti sempre più complessi.
Il concetto di spazio e di tempo
Nei capitoli precedenti vi ho parlato del concetto di maggiore o minore peso, quindi di maggior o minore importanza dell’informazione, che porta i neuroni, tramite le varie sinapsi, a “categorizzare” tutti i dati prediligendone alcuni anziché altri. Questo processo di conferimento dell’importanza non avviene perché i segnali che vengono trasferiti dalle varie sinapsi hanno un’intensità differente, quindi ci sono quelli più o meno importanti. Tutti i segnali vengono trasferiti alla stessa maniera e intensità. Quello che cambia è la quantità di segnali che possono arrivare da differenti parti del cervello e la correlazione temporale tra questi segnali. Il primo caso è abbastanza semplice da capire, poiché i segnali possono essere molteplici e derivare da differenti parti del cervello, mentre il secondo caso, quello temporale, è un po’ più ostico, nonché più difficile da riprodurre in un sistema artificiale.
Nel nostro cervello può accadere che un singolo neurone (per facilitare, possono essere anche più neuroni, ma non in numero tale da creare una quantità significativa rispetto alla totalità) invii in continuazione un segnale “isolato”, che viene raccolto dalle sinapsi, o che più neuroni inviino un segnale “solitario”, non ripetuto nel tempo. In entrambi i casi si tratta di situazioni che difficilmente possono dare importanza a una determinata informazione. Nel primo caso si tratta di segnali continuativi ma “spazialmente” limitati, quindi non in numero tale da essere percepiti come importanti. Nel secondo caso si tratta di un’informazione “temporalmente” limitata, cioè quel tipo di informazione è stata rilevante solo per poco tempo. Facciamo un esempio pratico, riprendendo proprio la conversazione con il Dott. Ricciardi. Appena abbiamo iniziato la videocall, il nostro cervello è stato bombardato da un sacco d’informazioni: abbiamo visto per la prima volta il nostro interlocutore, abbiamo guardato come era vestito, dove si trovata, il colore della parete retrostante, gli altri oggetti che erano presenti nella scena, abbiamo ascoltato il timbro della voce, la qualità della voce (in termini di trasmissione audio), la qualità del video, etc etc. Tutte queste informazioni hanno “eccitato” i nostri neuroni che hanno iniziato a scambiare informazioni, ma solo alcune di queste informazioni sono state considerate più importanti di altre. I neuroni che ci dicevano di guardare il colore della parete dietro al nostro interlocutore sono presto stati ignorati, così come l’aspetto o gli altri elementi della scena, abbiamo dato più retta ai neuroni che ci dicevano di valutare la qualità dell’audio, e dopo aver iniziato la conversazione i legami più forti sono stati creati dai neuroni che ci mandavano le informazioni sul contenuto della conversazione, mettendo in secondo piano tutto il resto.

Tutto ciò è accaduto e accade perché temporalmente i nostri neuroni / sinapsi “concentrati” sulla conversazione hanno ricevuto da più neuroni e con una frequenza (temporale) elevata le informazioni sul contenuto della conversazione, e ciò ha messo in secondo piano tutto il resto.
Biologicamente parlando è spesso più importante questa capacità di identificare i segnali nel tempo piuttosto che la dimensione spaziale, ed è molto difficile implementare il funzionamento sull’hardware. Molto sistemi neuromorfici nascono senza questa peculiarità e mediamente, per riprodurre il concetto tempo, i segnali in uscita (i dati risultati dai calcoli dei chip) vengono reinseriti nel sistema come a creare un loop continuo (Recurrent Neural Network)
Riprodurre questo comportamento del cervello è molto difficile a livello hardware, ma biologicamente parlando spesso è molto più importante per pesare le informazioni.
La neuroplasticità
Un altro concetto che i ricercatori devono riprodurre all’interno dei chip neuromorfici è il concetto di plasticità del cervello, cioè la sua capacità di specializzarsi, organizzarsi e adattarsi a fronte dell’esperienza o necessità. Come sappiamo il nostro cervello è suddiviso in zone, alcune adibite alla comprensione dei suoni, altre del gusto, altre reagiscono alle emozioni, altre permettono di muoverci in un ambiente tridimensionale, etc. Tutto ciò non è geneticamente codificato nel nostro DNA, bensì il cervello evolve e si adatta in base agli stimoli e quello che viviamo. Con l’esperienza e la necessità varie zone del cervello si specializzano, e diventano migliori e più capaci nell’elaborare e gestire i differenti tipi di dati che assumiamo continuamente. Questo concetto di plasticità diventa estremamente chiaro, ad esempio, nel caso di traumi, dove una parte del cervello viene fisicamente danneggiata e conseguentemente si subisce una perdita di capacità (in base alla zona che viene danneggiata). Ma successivamente il cervello è in grado di riorganizzarsi e con il tempo è possibile riguadagnare la capacità persa.
I chip neuromorfici, grazie alla loro capacità di immagazzinare le informazioni a livello di “neurone artificiale”, a lungo andare possono migliorare e specializzarsi in determinate funzioni e azioni, in base a quanto vengono allenati e stimolati, seguendo il comportamento descritto precedentemente.
Cosa permetteranno di fare
Anche se abbiamo scalfito solo la superficie, ora dovrebbe essere un po’ più chiaro cosa s’intende per informatica o chip neuromorfici. Fino ad ora ho tuttavia dato per scontato che i lettori conoscessero il funzionamento basilare di un computer moderno e fossero in grado di individuare le differenze rispetto un sistema neuromorfico. Nel caso in cui non sia così, ripercorriamo velocemente le basi di funzionamento di un computer moderno così che tutto quanto appreso fino ad ora possa assumere un significato ancora più chiaro.
Un computer moderno è in grado di effettuare operazioni secondo degli schemi prefissati. Le operazioni che effettuate con un software vengono tradotte in linguaggio binario secondo specifici algoritmi. I dati vengono scambiati tra i differenti componenti che compongono un computer (e differenti componenti all’interno dei singoli elementi, come le CPU), e tutto quello che accade è il risultato di calcoli ben definiti. Certo esiste una logica che permette ai computer moderni di effettuare delle scelte, ma queste scelte sono il risultato di una serie di azioni: “se si verifica questa condizione, allora la prossima azione da fare è questa”, etc.

Come abbiamo detto l’architettura Von Neumann e il linguaggio binario è molto limitato sotto il punto di vista del modo in cui i dati vengono elaborati. È comunque possibile andare oltre “l’ottusità” di un sistema informatico che basa le sue scelte solo sul verificarsi di certe condizioni le cui reazioni sono “codificate” (cioè previste) all’interno del sistema, e l’esempio più eclatante sono tutte le intelligenze artificiali di cui oggi si parla continuamente (ad esempio i sistemi in grado di riconoscere le immagini, la scrittura a mano libera, le conversazioni, etc). Tuttavia questa “intelligenza” delle IA non è altro che il risultato di algoritmi complessi, che vengono allenati per una determinata funzione. È una sorta di “intelligenza simulata”, cioè gli algoritmi sono talmente complessi che sembra di avere a che fare con sistemi in grado di pensare, ma in realtà il risultato si ottiene effettuando gli stessi calcoli che effettua un software banale, semplicemente elevati a una potenza in termini di quantità (e se vogliamo di “qualità” dell’algoritmo).
L’informatica neuromorfica non permetterà di “fare cose differenti rispetto a quelle che si possono fare oggi con le IA attuali”, ma consentirà di farlo in maniera più efficiente e con prestazioni più elevate, proprio perché cambia il modo in cui i dati sono analizzati ed elaborati.Certo la maggior potenza di calcolo ed efficienza permetterà di sviluppare IA più intelligenti e in grado di fare ragionamenti e attività più complesse rispetto a quanto accade oggi, ma quello che stiamo cercando di dire è che non cambierà il fine, bensì il modo in cui si raggiungerà quel fine.
C’è ancora molto da fare
Nonostante non se ne senta molto parlare fuori dall’ambiente accademico e scientifico, l’informatica neuromorfica è in pieno sviluppo da molti anni ed esistono attualmente sistemi e singoli chip per questo approccio, tra cui ad esempio i processori neuromorfici Intel Loihi. Ma c’è ancora tantissimo da fare e attualmente si possono identificare due correnti di sviluppo. Coloro che cercano di sviluppare l’hardware per renderlo sempre più simile al cervello, andando di pari passo alla ricerca biologica e inserendo nei chip solo gli elementi che possono sostituire le controparti biologiche. In questo caso la sfida più grande è trovare un modo per emulare in maniera efficace la dipendenza temporale, di cui parlavamo precedentemente. La seconda corrente di sviluppo è quella più “commerciale”, cioè delle varie aziende che cercano di sviluppare dei sistemi che, anche se si discostano dalla correttezza biologica, sono in grado di offrire prestazioni di calcolo superiori a quelle dei sistemi tradizionali, simulando il modo in cui il nostro cervello elabora i dati. Di fatto vengono realizzati degli acceleratori basati sul concetto di “Vector Matrix Multiplication”, che hanno lo scopo di simulare il funzionamento del cervello con le soluzioni tecnologiche ad oggi disponibili, piuttosto che sviluppare nuovi dispositivi e concetti tecnologici.
In ogni caso, se siamo lontani da avere dispositivi che si comportano veramente come i neuroni e le varie sinapsi, siamo molto avanti nel simularne i comportamenti. Ciò significa che non si possono ottenere le stesse prestazioni ed efficienza del cervello perché tali comportamenti sono ottenuti con molte più operazioni rispetto a quelle che naturalmente è in grado di fare il nostro cervello. In questo caso lo sviluppo tecnologico ha l’obiettivo di migliorare l’hardware per rendere tutto più efficiente e potente, fino a che la ricerca non otterrà risultati tali da rivoluzionare completamente il modo in cui l’hardware è pensato, introducendo, come è stato per i Memresistor, addirittura nuovi componenti.