



L'intelligenza artificiale sta attraversando una trasformazione fondamentale che gli addetti ai lavori definiscono "l'era dell'inferenza". Non si tratta più soltanto di addestrare modelli sempre più sofisticati, ma di garantire che questi sistemi possano rispondere a milioni di utenti in tempo reale, con costi sostenibili e prestazioni costanti. È in questo contesto che Google Cloud ha annunciato il lancio di Ironwood, la settima generazione delle sue Tensor Processing Unit (TPU), chip personalizzati progettati specificamente per le esigenze dell'intelligenza artificiale moderna. Insieme a Ironwood arrivano anche nuove istanze virtuali basate su processori Axion, l'architettura Arm sviluppata internamente da Google per ottimizzare i carichi di lavoro generici che supportano le applicazioni AI.
La portata di questa innovazione è tangibile: Anthropic, l'azienda che sviluppa Claude, uno dei modelli linguistici più avanzati al mondo, ha annunciato l'intenzione di utilizzare fino a un milione di TPU per gestire le proprie operazioni. James Bradbury, responsabile del computing di Anthropic, ha sottolineato come i miglioramenti nelle prestazioni di inferenza e nella scalabilità dell'addestramento di Ironwood permetteranno all'azienda di crescere in modo efficiente mantenendo la velocità e l'affidabilità che i clienti richiedono. Non sono solo le grandi aziende a beneficiarne: startup come Lightricks stanno già testando questa tecnologia per potenziare i loro modelli generativi multimodali open source.

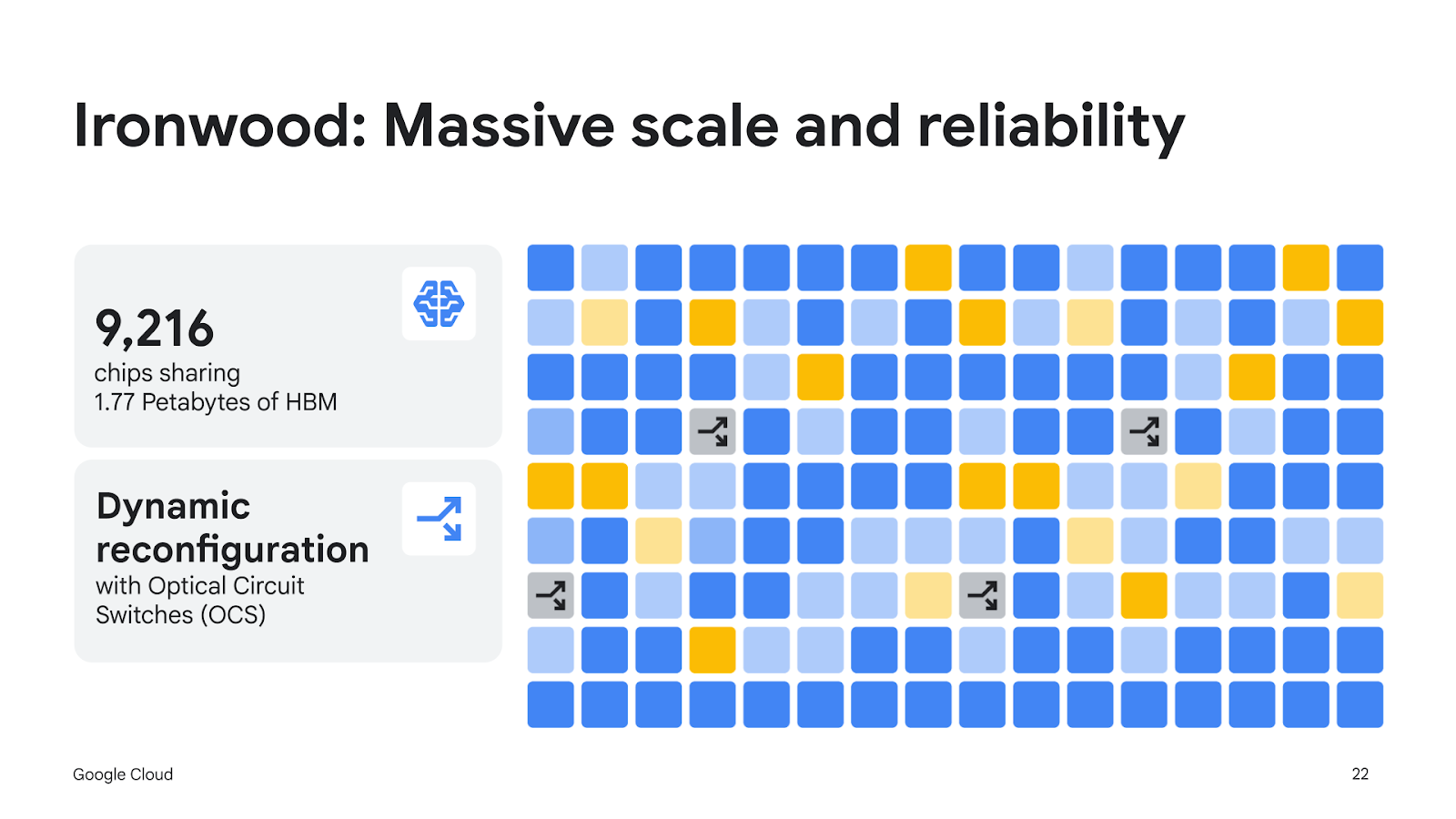
Il cuore dell'innovazione di Ironwood risiede nella sua capacità di interconnessione senza precedenti. Un singolo "pod", ovvero l'unità base di calcolo distribuito, può collegare fino a 9.216 chip che lavorano come un unico supercomputer. Per rendere l'idea: se ogni persona sulla Terra eseguisse un calcolo al secondo, servirebbero diversi giorni per eguagliare quanto questo sistema elabora in un solo secondo. La tecnologia Inter-Chip Interconnect (ICI) proprietaria di Google permette a questi chip di comunicare a una velocità di 9,6 terabit al secondo, eliminando i colli di bottiglia che tipicamente rallentano i sistemi di calcolo distribuito.
Questa capacità di memoria condivisa equivale all'archiviazione di circa 40.000 film in alta definizione o al testo di milioni di libri, tutti accessibili istantaneamente da migliaia di processori simultaneamente. È proprio questa caratteristica che consente ai modelli di intelligenza artificiale più complessi di operare senza le tipiche interruzioni causate dal dover continuamente recuperare dati da memorie più lente. La differenza rispetto alla concorrenza è netta: secondo i dati forniti da Google, Ironwood offre 118 volte più potenza di calcolo FP8 ExaFLOPS rispetto al principale concorrente, un divario che rappresenta non un semplice miglioramento incrementale ma un cambio di scala radicale.
L'affidabilità è un altro elemento cruciale in questa architettura. La tecnologia Optical Circuit Switching (OCS) agisce come un sistema nervoso dinamico che reindirizza istantaneamente il traffico dati in caso di interruzioni, garantendo che i servizi continuino a funzionare senza soluzione di continuità. Secondo un recente rapporto IDC, i clienti dell'AI Hypercomputer di Google (il sistema integrato di supercalcolo che include le TPU) hanno registrato in media un ritorno sull'investimento del 353% nell'arco di tre anni, una riduzione del 28% dei costi IT e team IT più efficienti del 55%.
Ma l'intelligenza artificiale moderna non vive solo di acceleratori specializzati. I flussi di lavoro agentici, sistemi AI che orchestrano multiple operazioni in sequenza, richiedono anche processori general-purpose efficienti per gestire preparazione dei dati, ingestion e hosting delle applicazioni. È qui che entrano in gioco le nuove istanze Axion, basate su architettura Arm e progettate da Google per offrire fino al doppio del rapporto prezzo-prestazioni rispetto alle VM x86 comparabili della generazione attuale.
La storia di Google nel campo del silicio personalizzato è lunga e interconnessa con l'evoluzione stessa dell'intelligenza artificiale moderna. La prima TPU, sviluppata dieci anni fa, ha reso possibile l'invenzione dell'architettura Transformer otto anni fa – la stessa che alimenta praticamente tutti i modelli AI contemporanei, da ChatGPT a Gemini. Questa tradizione include anche le Video Coding Unit per YouTube e cinque generazioni di chip Tensor per dispositivi mobili, tutti esempi di come la co-progettazione profonda tra ricerca sui modelli, software e hardware sotto lo stesso tetto possa generare innovazioni impossibili da ottenere altrimenti.
Il portfolio Axion si è ora ampliato con tre opzioni: N4A per carichi di lavoro general-purpose come microservizi e database open source, C4A per prestazioni consistentemente elevate con networking fino a 100 Gbps, e la nuova C4A metal, la prima istanza bare-metal basata su Arm di Google, dedicata a carichi di lavoro specializzati come sviluppo Android, sistemi automobilistici in-car e simulazioni complesse. Questa varietà permette alle aziende di ottimizzare costi e prestazioni selezionando l'istanza più adatta alle caratteristiche specifiche di ciascun carico di lavoro.
Sul fronte software, Google sta potenziando l'intero stack per massimizzare le capacità hardware di Ironwood. Il Cluster Director in Google Kubernetes Engine ora offre funzionalità avanzate di manutenzione e consapevolezza della topologia per cluster altamente resilienti. MaxText, il framework open source ad alte prestazioni per LLM, è stato migliorato per facilitare l'implementazione delle più recenti tecniche di ottimizzazione come il Supervised Fine-Tuning e il Generative Reinforcement Policy Optimization. Per l'inferenza, il supporto migliorato per le TPU in vLLM consente agli sviluppatori di passare tra GPU e TPU con modifiche minime alla configurazione.

.jpg)



{kind=link}