



Nel campo dell'intelligenza artificiale, il problema di come far evolvere autonomamente i sistemi senza supervisione umana costante rappresenta una delle sfide più complesse. Un gruppo di ricerca composto da scienziati di Meta FAIR e della National University of Singapore ha messo a punto un approccio innovativo che ribalta la logica tradizionale: invece di alimentare i modelli con dataset predefiniti, li fa competere contro se stessi in un ambiente basato su documenti reali. Il risultato è SPICE (Self-Play In Corpus Environments), un framework di reinforcement learning che promette di superare i limiti delle tecniche attuali.
Le metodologie convenzionali per l'auto-miglioramento dell'AI si scontrano con ostacoli significativi. L'approccio più diffuso, il reinforcement learning con ricompense verificabili, dipende fortemente da set di problemi curati manualmente e da sistemi di ricompensa specifici per ogni dominio, rendendone difficile l'espansione. Anche il self-play, dove un modello migliora confrontandosi con se stesso, ha mostrato gravi limitazioni: gli errori fattuali nelle domande e risposte generate si amplificano creando un circolo vizioso di allucinazioni, mentre la simmetria informativa tra chi genera i problemi e chi li risolve porta a sfide ripetitive e poco stimolanti.
La soluzione proposta da SPICE si basa su un'architettura duale che elimina proprio questa simmetria informativa. Un singolo modello opera simultaneamente in due ruoli distinti: il "Challenger" costruisce un curriculum di problemi sempre più complessi attingendo da un vasto corpus documentale, mentre il "Reasoner" tenta di risolvere questi problemi senza avere accesso ai documenti originali. Questa separazione fondamentale impedisce la stagnazione che affligge altri metodi di auto-apprendimento.
L'ancoraggio ai documenti reali costituisce l'elemento chiave per prevenire le allucinazioni, uno dei problemi più persistenti nei modelli linguistici di grandi dimensioni. Come sottolineano i ricercatori nel loro studio pubblicato su arXiv, l'auto-miglioramento richiede necessariamente l'interazione con fonti esterne che forniscano feedback diversificato e verificabile, piuttosto che una semplice introspezione a ciclo chiuso. In altre parole, gli agenti AI devono imparare dall'esperienza del mondo reale e dalle interazioni umane, non solo dai propri output.
La dinamica competitiva tra i due ruoli genera automaticamente un percorso formativo progressivo. Il Challenger riceve ricompense quando crea problemi che risultano sufficientemente difficili ma non impossibili, posizionandosi esattamente alla frontiera delle capacità del Reasoner. Quest'ultimo viene invece premiato per le risposte corrette. Questa interazione simbiotica spinge entrambi gli agenti a scoprire e superare continuamente nuove sfide, in un processo di co-evoluzione.
La flessibilità del sistema rappresenta un vantaggio notevole rispetto ai metodi precedenti. Utilizzando documenti grezzi invece di coppie domanda-risposta predefinite, SPICE può generare formati di compito diversificati, dalle domande a scelta multipla a quelle a risposta aperta. Questo elimina il vincolo che confinava le tecniche precedenti a campi ristretti come matematica e programmazione, aprendo potenzialmente a qualsiasi dominio specialistico, dall'analisi legale a quella medica, senza dipendere da costosi dataset curati manualmente.
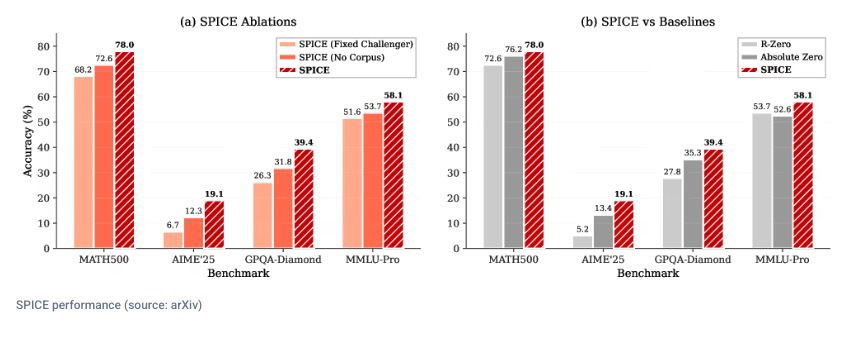
I test condotti su diversi modelli base, tra cui Qwen3-4B-Base e OctoThinker-3B-Hybrid-Base, hanno confermato l'efficacia dell'approccio. Le performance sono state confrontate con vari baseline, inclusi modelli senza addestramento specifico, modelli addestrati con un Challenger fisso e potente, e metodi di self-play puro come R-Zero e Absolute Zero. I risultati mostrano che SPICE ha costantemente superato le alternative su un'ampia gamma di benchmark di ragionamento matematico e generale.
Un dato particolarmente significativo emerso dalla sperimentazione riguarda l'evoluzione parallela dei due agenti. Durante l'addestramento, il tasso di successo del Reasoner su un set fisso di problemi è aumentato dal 55% all'85%, dimostrando il miglioramento delle sue capacità. Contemporaneamente, le versioni più recenti del Challenger sono riuscite a generare domande che hanno ridotto il tasso di successo di un Reasoner nelle fasi iniziali dal 55% al 35%, confermando che entrambi i ruoli si sviluppano efficacemente in tandem.
Secondo i ricercatori, questo lavoro segna un cambio di paradigma nei metodi di ragionamento auto-miglioranti: dalla stagnazione del self-play a ciclo chiuso, spesso compromesso dalla deriva allucinogena, verso un miglioramento aperto attraverso l'interazione con la vasta conoscenza verificabile incorporata nei corpus documentali del web. Al momento, il corpus utilizzato rappresenta l'esperienza umana catturata in formato testuale, ma l'obiettivo finale è estendere questi sistemi alle interazioni con la realtà fisica, internet e gli esseri umani attraverso multiple modalità come video, audio e dati sensoriali.
Sebbene SPICE sia ancora un proof-of-concept, il meccanismo di self-play che propone potrebbe costituire la base per futuri sistemi AI capaci di adattarsi dinamicamente ai loro ambienti. La capacità di generare autonomamente sfide sempre più complesse e di apprendere da fonti di conoscenza esterne potrebbe rendere questi sistemi più robusti di fronte all'imprevedibilità delle applicazioni nel mondo reale, un requisito essenziale per la loro diffusione oltre i contesti di laboratorio controllati.

.jpg)



{kind=link}