

Sul finire del 2017 Intel annunciò l’intenzione di tornare nel mondo delle GPU dedicate, dando in mano le chiavi dell’intera operazione a Raja Koduri, ex capo del Radeon Technologies Group di AMD. Koduri, da allora chief architect di Intel e senior vice president del nuovo Core e Visual Computing Group, ha lavorato in questi anni su quella che conosciamo come architettura Xe, un progetto in grado di scalare dai computer ultramobile fino ai supercomputer exascale e all'allenamento di intelligenze artificiali, il tutto sfruttando un unico modello di programmazione.

Intel non è ancora pronta a discutere nel dettaglio come applicherà l’architettura Xe a tutti i segmenti di mercato, ma in queste ore ha diffuso le prime informazioni su “Ponte Vecchio”, il suo primo acceleratore di classe exascale in arrivo nel 2021 dedicata al settore HPC, quello dei supercomputer. Ponte Vecchio come uno dei simboli della città di Firenze, il caratteristico ponte che attraversa il fiume Arno.
Tre i tratti “hardware” distintivi di Intel Ponte Vecchio: l’uso del processo produttivo a 7 nanometri per la realizzazione dei chiplet, le tecnologie di packaging Foveros ed EMIB e l’interconnessione Xe Link (basata sullo standard CXL - Compute Express Link -, a sua volta derivato dal PCIe 5.0) per il collegato tra GPU.
Passando all'architettura Xe, almeno in questa incarnazione, troviamo un flexible data-parallel vector matrix engine cruciale per le operazioni di intelligenza artificiale. Xe assicura inoltre un throughput con calcoli in virgola mobile a doppia precisione (FP64) elevato, requisito importante non per l'ambito AI ma per carichi tradizionali come le simulazioni meteo, la ricerca di combustibili fossili, ecc. Infine una quantità elevata di cache e bandwidth di memoria (probabilmente grazie all'uso di memoria HBM), che in base alla slide sarà collegata direttamente ai singoli chiplet di calcolo.


Vedremo Ponte Vecchio a bordo del supercomputer Aurora che sarà installato presso l’Argonne National Laboratory nel 2021, ma anche in HPC creati da Atos e Lenovo. Si tratterà di un sistema exascale, ossia capace di svolgere almeno un exaFLOP di calcoli al secondo (un miliardo di miliardi di operazioni al secondo).
In un singolo nodo di Aurora ci saranno due CPU Xeon Scalabile “Sapphire Rapids” (architettura post Ice Lake a 10 nanometri) e sei GPU Ponte Vecchio unite da un’architettura di memoria unificata e una connettività pensata per garantire bassa latenza e alto bandwidth. Complessivamente si parla di oltre 10 petabyte di memoria, 230 petabyte di archiviazione e oltre 200 rack.
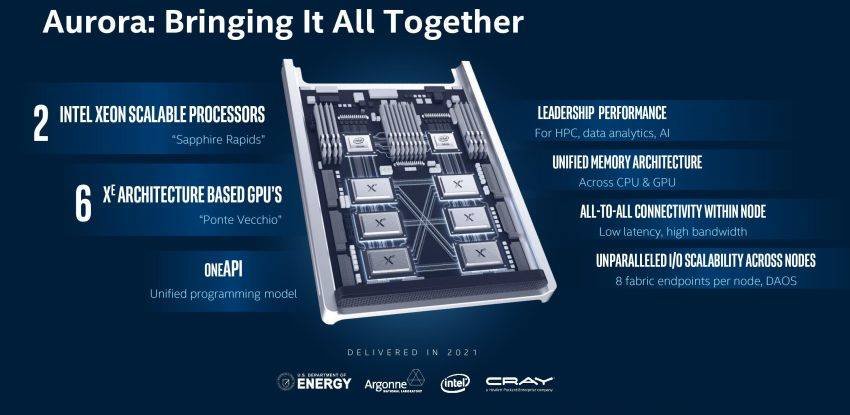
Il tutto funzionerà insieme grazie OneAPI, un modello di programmazione unificato basati su standard industriali e specifiche aperte pensato per semplificare lo sviluppo tra diverse architetture. Facilità d’uso e prestazioni, ma anche l’addio a differenti codici base e linguaggi di programmazione, nonché strumenti e flussi di lavoro diversi.
Più nello specifico One API contiene un nuovo linguaggio di programmazione diretto e aperto, Data Parallel C++ (DPC++). È basato su C++, incorpora SYCL di Kronos Group ed estensioni sviluppate tramite un processo aperto insieme alla comunità.
Una scelta coraggiosa e ambiziosa quella di Intel, che però sembra quasi una strada obbligata visto che a differenza di altre realtà sta perseguendo, specie nel mondo delle intelligenza artificiali, una strategia basata su più prodotti: CPU, GPU, FPGA e acceleratori specializzati. Il tutto è definito dall’azienda xPU.




L’azienda ha reso disponibile OneAPI su Intel DevCloud, una sandbox di sviluppo per mettere a punto, testare e svolgere vari carichi di lavoro su CPU, GPU e FPGA. L’obiettivo è quello di permettere agli sviluppatori di prendere confidenza con OneAPI. Intel ha infine creato uno tool di migrazione che converte il codice CUDA in OneAPI, un chiaro tentativo di fare concorrenza al linguaggio di programmazione di Nvidia.