



Il dibattito sulla capacità di ragionamento dei grandi modelli linguistici ha raggiunto toni accesi dopo la pubblicazione di uno studio controverso da parte di Apple, intitolato "L'illusione del pensiero". La ricerca sostiene che questi sistemi di intelligenza artificiale si limiterebbero a riconoscere pattern predefiniti, senza sviluppare alcuna vera forma di pensiero. Tuttavia, questa tesi presenta fragilità logiche evidenti che meritano un'analisi più approfondita.
Per comprendere se i modelli linguistici possano realmente pensare, occorre innanzitutto definire cosa intendiamo per "pensiero" nel contesto della risoluzione di problemi. Il cervello umano, quando affronta una sfida cognitiva, attiva diverse aree cerebrali in sequenza: la corteccia prefrontale gestisce la memoria di lavoro e le funzioni esecutive, permettendoci di scomporre il problema in componenti più piccole. La corteccia parietale codifica le strutture simboliche necessarie per affrontare enigmi matematici o logici.

La simulazione mentale rappresenta un aspetto cruciale del ragionamento umano e si manifesta attraverso due meccanismi distinti. Il primo è un loop auditivo che ci consente di dialogare con noi stessi, un processo sorprendentemente simile alla generazione del chain-of-thought nei modelli linguistici. Il secondo è l'immaginazione visiva, che permette di manipolare oggetti mentalmente nello spazio tridimensionale. Questa capacità visuo-spaziale, collegata alla corteccia visiva e alle aree parietali, si è evoluta per la necessità di navigare efficacemente nel mondo fisico.
I ricercatori di Apple hanno basato le loro conclusioni su un esperimento apparentemente solido: hanno chiesto ai modelli di ragionamento di risolvere problemi sempre più complessi seguendo algoritmi predefiniti, osservando che le prestazioni degradavano con l'aumentare della difficoltà. Ma questa argomentazione contiene una falla logica fondamentale. Se chiedessimo a un essere umano che conosce l'algoritmo per risolvere il problema della Torre di Hanoi con venti dischi, quasi certamente fallirebbe nel completare il compito. Seguendo la stessa logica applicata ai modelli linguistici, dovremmo concludere che nemmeno gli esseri umani possono pensare.
Esiste una condizione neurologica chiamata afantasia che colpisce alcune persone, impedendo loro di formare immagini mentali spaziali. Eppure, chi ne soffre può pensare perfettamente e condurre una vita normale senza percepire alcuna limitazione significativa. Molti di loro eccellono nel ragionamento simbolico e nelle discipline matematiche, compensando brillantemente l'assenza di visualizzazione mentale. Questo dimostra che il pensiero non richiede necessariamente tutte le facoltà cognitive che associamo al ragionamento umano completo.
Osservando il processo cognitivo umano da una prospettiva più astratta, emergono tre elementi fondamentali: il riconoscimento di pattern per richiamare esperienze apprese e rappresentare problemi, la memoria di lavoro per conservare i passaggi intermedi, e la capacità di tornare sui propri passi quando una linea di ragionamento si rivela infruttuosa. Nei modelli linguistici di grandi dimensioni, il riconoscimento di pattern deriva dall'addestramento, che insegna sia la conoscenza del mondo sia i pattern per elaborarla efficacemente.
La struttura a strati di questi modelli impone che l'intera memoria di lavoro debba essere contenuta all'interno di un singolo livello computazionale. I pesi della rete memorizzano la conoscenza e i pattern da seguire, mentre l'elaborazione avviene tra i livelli utilizzando i pattern appresi e memorizzati come parametri del modello. Nel meccanismo di chain-of-thought, l'intero testo — compreso l'input, il ragionamento intermedio e la parte di output già generata — deve essere contenuto in ogni strato, con la memoria di lavoro rappresentata da un singolo livello attraverso la cache delle chiavi-valori nel meccanismo di attenzione.
Esiste evidenza concreta che i modelli con chain-of-thought possano fare passi indietro quando una determinata linea di ragionamento appare improduttiva. Paradossalmente, proprio ciò che i ricercatori di Apple hanno osservato nei loro esperimenti rafforza questa tesi: i modelli hanno correttamente riconosciuto che tentare di risolvere direttamente puzzle complessi avrebbe superato la capacità della loro memoria di lavoro, cercando quindi scorciatoie alternative, esattamente come farebbe un essere umano.
Una rappresentazione della coscienza?
Una critica comune sostiene che i sistemi di predizione del prossimo token non possono pensare perché si limitano a funzionare come un "completamento automatico glorificato". Questa prospettiva fraintende profondamente la natura del compito. La predizione della prossima parola non rappresenta affatto una forma limitata di rappresentazione del pensiero, ma piuttosto costituisce la forma più generale di rappresentazione della conoscenza che si possa immaginare.
Qualsiasi sistema per rappresentare conoscenza richiede un linguaggio o un sistema simbolico. I linguaggi formali esistenti sono molto precisi in ciò che possono esprimere, ma fondamentalmente limitati nei tipi di conoscenza rappresentabile. La logica dei predicati del primo ordine, ad esempio, non può rappresentare proprietà relative a tutti i predicati che soddisfano una certa caratteristica, perché non ammette predicati su predicati. Anche i calcoli predicativi di ordine superiore, che possono rappresentare predicati su predicati a profondità arbitrarie, falliscono nell'esprimere idee prive di precisione o di natura astratta.
Il linguaggio naturale, invece, possiede completezza nel potere espressivo: può descrivere qualsiasi concetto a qualsiasi livello di dettaglio o astrazione. È persino possibile descrivere concetti relativi al linguaggio naturale usando il linguaggio naturale stesso, una proprietà di auto-referenzialità che lo rende un candidato eccellente per la rappresentazione della conoscenza. La sfida consiste nel fatto che questa ricchezza espressiva rende più complesso elaborare le informazioni codificate, ma non è necessario comprendere manualmente come farlo: possiamo semplicemente programmare la macchina attraverso i dati, mediante un processo chiamato addestramento.
Un sistema di predizione del prossimo token calcola essenzialmente una distribuzione di probabilità sul token successivo, dato un contesto di token precedenti. Qualsiasi macchina che miri a calcolare questa probabilità accuratamente deve necessariamente rappresentare in qualche forma la conoscenza del mondo. Consideriamo la frase incompleta: "La vetta montuosa più alta del mondo è il Monte..." — per predire correttamente "Everest" come parola successiva, il modello deve avere questa conoscenza memorizzata da qualche parte. Se il compito richiede di calcolare una risposta o risolvere un enigma, il predittore deve generare token di chain-of-thought per portare avanti la logica.
Ciò implica che, nonostante predica un token alla volta, il modello deve rappresentare internamente almeno i prossimi token nella sua memoria di lavoro, sufficienti per garantire di rimanere sul percorso logico corretto. Gli esseri umani, in fondo, predicono anch'essi il prossimo token, sia durante il discorso sia quando pensano utilizzando la voce interiore. Un sistema di completamento automatico perfetto che produce sempre i token corretti dovrebbe essere onnisciente, un traguardo irraggiungibile poiché non tutte le risposte sono computabili.
Può imparare a pensare?
Tuttavia, un modello parametrizzato capace di rappresentare conoscenza attraverso l'aggiustamento dei suoi parametri, e che può apprendere mediante dati e rinforzo, può certamente imparare a pensare. La prova definitiva del pensiero risiede nella capacità di un sistema di risolvere problemi che richiedono ragionamento. Se un sistema può rispondere a domande mai viste prima che richiedono un certo livello di ragionamento, deve aver appreso a pensare o quantomeno a ragionare verso la soluzione.
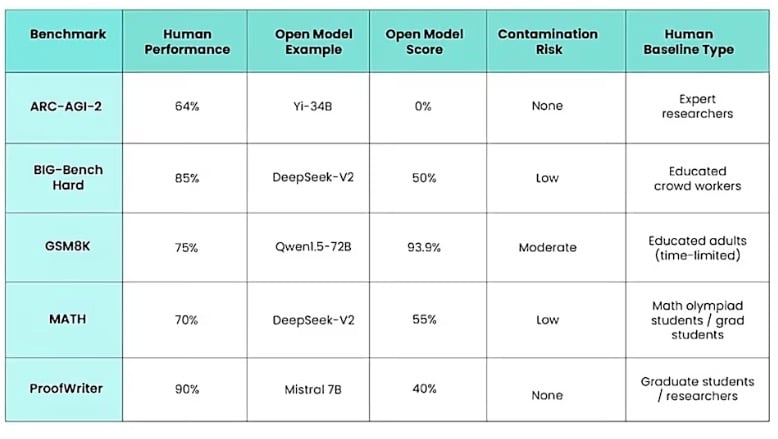
I modelli proprietari dimostrano prestazioni eccellenti in determinati benchmark di ragionamento, sebbene esista la possibilità che alcuni siano stati ottimizzati sui test set attraverso canali non trasparenti. Concentrandosi esclusivamente sui modelli open-source per garantire equità e trasparenza, emerge chiaramente che questi sistemi riescono a risolvere un numero significativo di domande basate sulla logica. Sebbene rimangano indietro rispetto alle prestazioni umane in molti casi, il confronto spesso avviene con individui specificamente addestrati su quei benchmark, mentre in alcune circostanze i modelli superano effettivamente la performance dell'essere umano medio non addestrato.
I risultati dei benchmark, la sorprendente somiglianza tra il ragionamento chain-of-thought e quello biologico, e la comprensione teorica che qualsiasi sistema con sufficiente capacità rappresentazionale, dati di addestramento adeguati e potenza computazionale può eseguire qualsiasi compito calcolabile, convergono verso una conclusione ragionevole. I modelli linguistici di grandi dimensioni soddisfano questi criteri in misura considerevole, suggerendo che possiedano effettivamente la capacità di pensare.





{kind=link}