

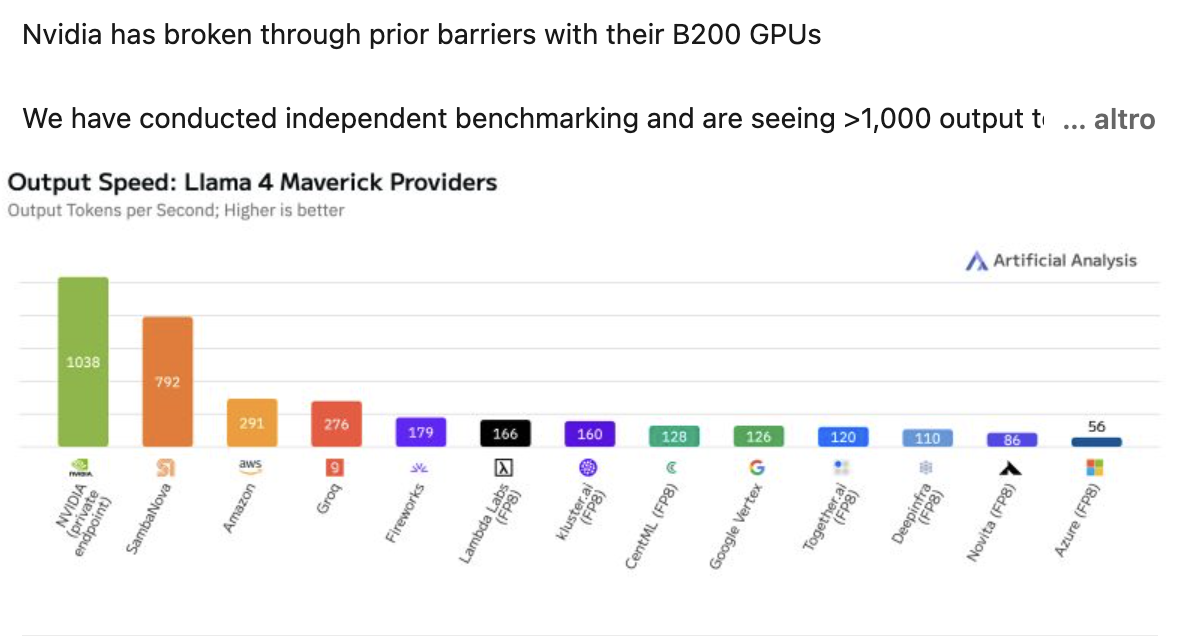
L'intelligenza artificiale continua la sua corsa alle prestazioni, con NVIDIA che segna un nuovo traguardo storico nel campo dell'elaborazione linguistica. Secondo quanto riportato da Artificial Analysis su LinkedIn, il colosso tecnologico ha superato per la prima volta la barriera dei 1.000 token al secondo (TPS) per utente utilizzando il modello linguistico Llama 4 Maverick di Meta. Questo risultato è stato ottenuto grazie al nuovissimo nodo DGX B200, equipaggiato con otto GPU Blackwell, l'ultima generazione di processori grafici dell'azienda. Con 1.038 TPS per utente, NVIDIA ha superato del 31% il precedente record detenuto da SambaNova, che si fermava a 792 TPS per utente.
La competizione per la velocità di elaborazione nel campo dell'intelligenza artificiale vede pochi contendenti ai vertici. Amazon e Groq si sono avvicinate alla soglia dei 300 TPS per utente, mentre altre aziende come Fireworks, Lambda Labs, Google Vertex e Microsoft Azure hanno ottenuto risultati inferiori ai 200 TPS per utente. Questo divario significativo evidenzia quanto NVIDIA e SambaNova siano attualmente in una categoria a parte rispetto al resto del settore.
Il risultato record di Blackwell non è stato casuale, ma frutto di una serie di ottimizzazioni mirate all'architettura di Llama 4 Maverick. Gli ingegneri di NVIDIA hanno implementato estese modifiche software utilizzando TensorRT e hanno addestrato un modello di decodifica speculativa con tecniche Eagle-3. Queste ultime sono progettate per accelerare l'inferenza nei modelli linguistici di grandi dimensioni (LLM) predicendo i token in anticipo, un po' come quando il testo predittivo sugli smartphone anticipa quale parola potremmo voler digitare successivamente.
Questi due interventi da soli hanno portato a un aumento delle prestazioni di quattro volte rispetto ai precedenti migliori risultati ottenuti con Blackwell. Ma gli sforzi non si sono fermati qui: l'accuratezza è stata migliorata utilizzando tipi di dati FP8 (anziché BF16), operazioni di Attention ottimizzate e la tecnica Mixture of Experts, che ha rivoluzionato il mondo dell'IA quando è stata introdotta con il modello DeepSeek R1.
Per spingere ulteriormente le prestazioni, i tecnici NVIDIA hanno implementato numerose ottimizzazioni al kernel CUDA, tra cui il partizionamento spaziale e il GEMM weight shuffling. Queste tecniche, apparentemente oscure ai non addetti ai lavori, rappresentano in realtà raffinati interventi di microgestione delle risorse computazionali che permettono di spremere ogni singolo ciclo di calcolo dalle GPU.
Ma cosa rappresenta esattamente questa metrica TPS/utente che tanto entusiasma gli esperti? I token sono l'unità fondamentale dei modelli linguistici: quando digitiamo una domanda in ChatGPT o Copilot, le nostre parole e caratteri vengono convertiti in token. Il modello elabora questi token e produce una risposta basata su di essi secondo la sua programmazione. La specificazione "per utente" indica che il benchmark si concentra sull'esperienza individuale piuttosto che sull'elaborazione in batch di multiple richieste.
Questa misurazione è particolarmente importante per gli sviluppatori di chatbot AI, poiché influisce direttamente sull'esperienza dell'utente finale. Più velocemente un cluster di GPU può elaborare token per singolo utente, più rapidamente un chatbot AI risponderà alle domande. In termini pratici, significa conversazioni più fluide e naturali con gli assistenti virtuali, con tempi di attesa ridotti tra domanda e risposta.
L'impatto di questi progressi si estende ben oltre il semplice confronto tecnico tra aziende. La capacità di elaborare rapidamente grandi volumi di dati linguistici apre la strada a applicazioni AI sempre più reattive e capaci di gestire compiti complessi in tempo reale. Dai sistemi di traduzione istantanea agli assistenti virtuali specializzati, fino ai sistemi di supporto alla diagnosi medica, la velocità di elaborazione rappresenta spesso il confine tra un'esperienza utente accettabile e una veramente rivoluzionaria per il quotidiano.