


Nel corso della GTC 2024, Phison ha presentato un'inattesa novità nel campo dell'intelligenza artificiale: la società ha dimostrato come un'unica workstation dotata di quattro GPU potesse gestire carichi di lavoro per l'IA che normalmente richiederebbero ben 1,4 TB di VRAM su 24 GPU H100. Come ci è riuscita? Il merito è tutto del nuovo software Phison aiDaptiv+, che espande la memoria effettiva utilizzando SSD e DRAM e promette di rendere l'addestramento degli LLM accessibile a prezzi ridotti.
La piattaforma si rivolge a piccole e medie imprese e ad altri utenti che possono trarre vantaggio dall'utilizzo di modelli pre-addestrati per l'elaborazione di propri set di dati privati e vogliono contenere i costi; tuttavia, per quanto innovativa e interessante, la soluzione di Phison non può competere con i sistemi NVIDIA, ben più performanti. L'obiettivo è offrire una soluzione accessibile ed economica, perfetta per chi non ha bisogno di allenare i modelli velocemente.
Nel corso della dimostrazione, è stata utilizzata una workstation Pro AI di Maingear con un processore Xeon w7-3445X, 512GB di RAM DDR5-5600 e due SSD Phison da 2TB progettati per carichi di lavoro di caching. Interessante notare come i prezzi di questi sistemi variano da 28.000 dollari con una GPU fino a 60.000 dollari per un sistema con quattro GPU. Un costo considerevolmente più basso rispetto all'investimento necessario per configurare server di addestramento con sei o otto GPU, oltre a richiedere infrastrutture elettriche meno impegnative.
Per quanto riguarda l'addestramento, per un modello da 70 miliardi di parametri, la configurazione di un'unica workstation richiederà circa quattro volte il tempo rispetto a un sistema di 30 GPU distribuito su otto nodi. Tuttavia, Phison propone anche un'opzione di scale-out per ridurre questi tempi di formazione a poco più della metà del costo e ridurre così i tempi di addestramento a 1,2 ore per un modello da 70 miliardi di parametri, contro le 0,8 ore necessarie sul sistema a 30 GPU citato.
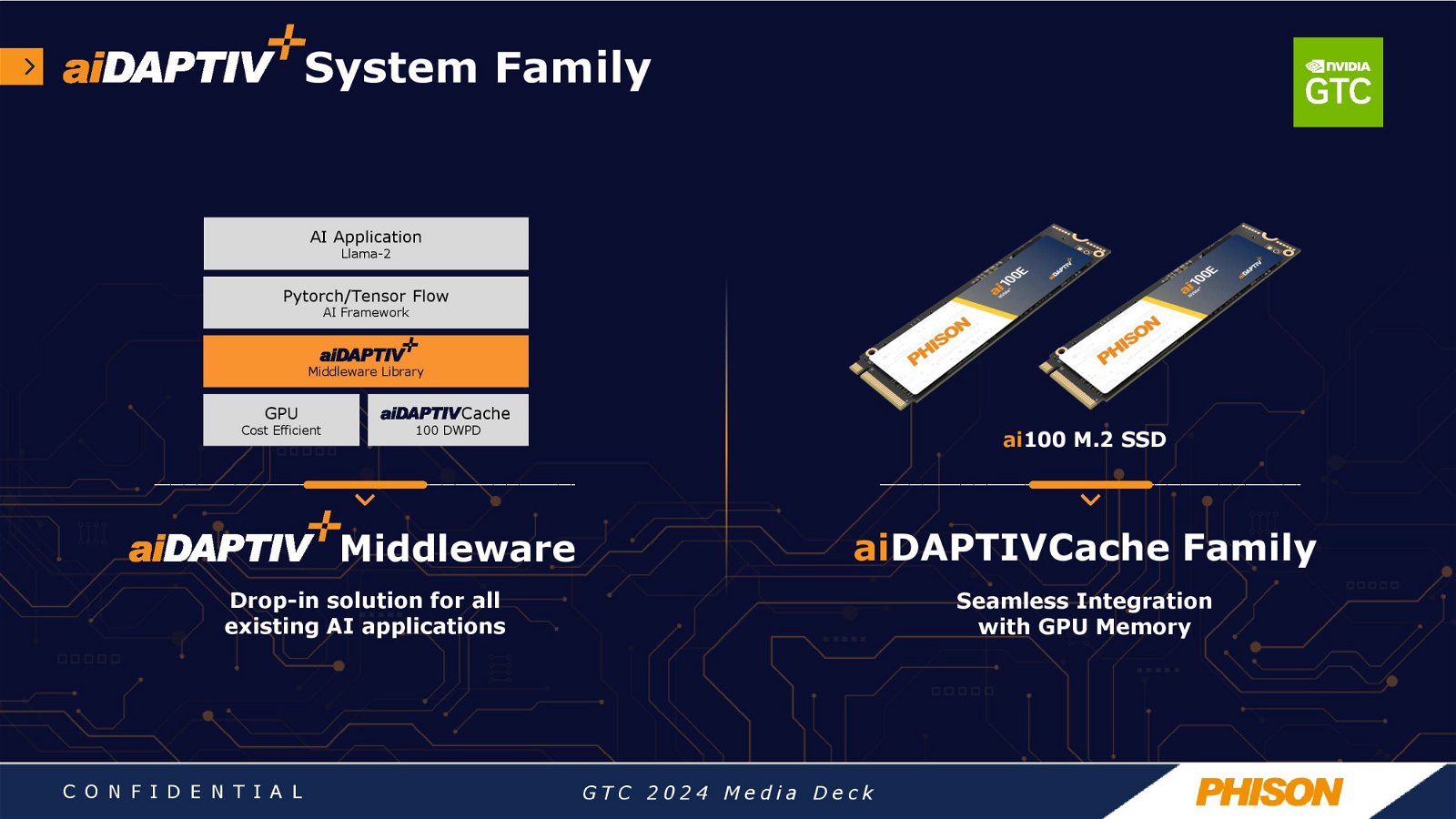
Phison ha anche introdotto gli SSD aiDaptiveCache ai100E in formato M.2, progettati specificamente per i carichi di lavoro di caching e basati su memoria flash SLC per migliorare sia le prestazioni che la durata. Questi SSD sono classificati per 100 scritture complete al giorno per cinque anni, attestandosi come soluzioni di storage di lunga durata rispetto agli SSD standard.
La piattaforma prevede l’uso di un middleware, denominato aiDaptive middleware, che opera al di sotto dei livelli di Pytorch/Tensor Flow, e che secondo Phison opera in modo trasparente senza richiedere modifiche alle applicazioni AI. Questo approccio non solo riduce drasticamente i costi di formazione dei modelli, ma offre anche la possibilità di scalare l'addestramento collegando più nodi.